DNの解析
格納されたトークンのDNを別のフォーマットに変換します。
フィールド
- 開始
-
開始のRDNインデックスを指定します。
-
インデックス0はルートに最も近いRDN
-
正のインデックスはルートに最も近いRDNからのオフセット
-
インデックス-1はリーフに最も近いセグメント
-
負のインデックスは、リーフに最も近いRDNからルートに最も近いRDN方向へのオフセット
-
- 長さ
-
含めるRDNのセグメントの数です。負の数は(セグメント総数+長さ) + 1のように解釈されます。たとえば、セグメント数が5のDNでは、長さが-1の場合は-1 = (5 + (-1)) + 1 = 5、長さが-2の場合は-2 = (5 + (-2)) + 1 = 4。
- ソースDNのフォーマット
-
ソースDNの解析に使用されるフォーマットを指定します。
- ターゲットDNのフォーマット
-
解析されたDNの出力に使用されるフォーマットを指定します。
- ソースDN区切り文字
-
ソースDNのフォーマットが[カスタム]に設定されている場合に、カスタムのソースDN区切り文字を指定します。
- ターゲットDN区切り文字
-
ターゲットDNのフォーマットが[カスタム]に設定されている場合に、カスタムのターゲットDN区切り文字を指定します。
備考
「開始」または「長さ」がデフォルト値{0、-1}に設定されている場合はDN全体が使用されます。それ以外の場合は、「開始」または「長さ」で指定されたDNの一部分が使用されます。
カスタムのDNフォーマットを指定する場合、区切り文字を構成する8文字は次のように定義されます。
-
タイプされた名前のブールフラグ: 0は名前が入力されていない、1は入力されていることを意味します。
-
Unicode*マップなし文字ブールフラグ: 0はマップできないUnicode文字(\FFFFなどのエスケープ文字付きの16進数文字列)を出力または解釈しないことを意味します。eDirectoryでは、Unicode文字の0xfeff、0xfffe、0xfffd、および0xffffは使用できません。
-
相対RDN区切り文字
-
RDN区切り文字
-
名前ディバイダ
-
名前の値の区切り文字
-
ワイルドカード文字
-
エスケープ文字
RDN区切り文字と相対RDN区切り文字が同じ文字である場合、名前の向きは右から左、それ以外の場合は左から右になります。
区切り文字セットが8文字を超える場合、超過した文字はエスケープ処理が必要な文字と見なされるだけで、それ以外の特別な意味は考慮されません。
例
この例では、DNの解析トークンを使用して、ターゲット属性値の追加アクションの値を作成します。例では、Identity Managerとともに提供される事前定義されたルールです。詳細については、コマンド変換-部署別コンテナの作成-パート1およびパート2を参照してください。 ポリシーをXMLで表示するには、predef_command_create_dept_container2.xmlを参照してください。
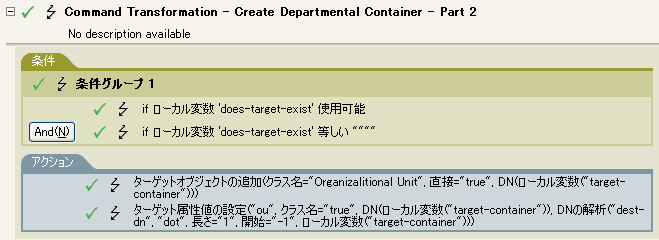

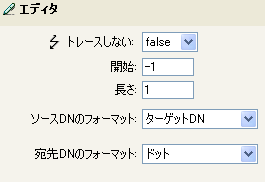
DNの解析トークンは、ソースDNから情報を取得し、これをドット表記に変更しています。DNの解析からの情報は、OUの属性値に保存されます。