2.4 Cluster-Gruppierung
Wenn Sie die Benutzeranwendung in einer Cluster-Umgebung verwenden, müssen Sie drei Dinge beachten:
- Die JBoss-Clusterkonfiguration (siehe Schnitt 2.4.1, JBoss-Cluster-Gruppierung)
- Die Caching-Konfiguration der Benutzeranwendung (siehe Schnitt 2.4.3, Konfigurieren des Cluster-Gruppen-Cachings der Benutzeranwendung)
- Die Konfiguration der Workflow-Engine (siehe Schnitt 2.4.4, Konfigurieren der Workflows für die Cluster-Gruppierung)
2.4.1 JBoss-Cluster-Gruppierung
Ein Cluster ist eine Sammlung von Anwendungsserverknoten, die mehrere Services bereitstellen. Ein Cluster hat den Zweck, die Leistung und die Zuverlässigkeit von Anwendungen zu steigern. In der Regel bietet ein Cluster Unternehmensanwendungen drei wesentliche Vorteile:
- Hochverfügbarkeit
- Skalierbarkeit (mehr Kapazität)
- Lastausgleich
Hochverfügbarkeit bedeutet, dass eine Anwendung in der eingesetzten Zeit zu einem hohen Prozentsatz zuverlässig und verfügbar ist. Cluster liefern eine hohe Verfügbarkeit, weil auf allen Knoten dieselbe Anwendung ausgeführt wird. Wenn bei einem Knoten eine Fehlfunktion auftritt, wird die Anwendung weiterhin auf den anderen Knoten ausgeführt. Die Identity Manager-Benutzeranwendung profitiert von einer höheren Verfügbarkeit, wenn sie in einem Cluster ausgeführt wird. Die Identity Manager-Benutzeranwendung unterstützt jedoch keine Reproduktion von HTTP-Sitzungen. Dies bedeutet, dass die Sitzungsinformationen verloren gehen, wenn bei einem Knoten, auf dem eine Sitzung läuft, eine Fehlfunktion auftritt.
Der Lastausgleich ist der Vorgang der Verteilung der Arbeitslast auf die Mitglieder eines Clusters. Das Ziel des Lastausgleichs ist eine Steigerung der Leistung. Ein Lastausgleich kann auf unterschiedliche Weise erzielt werden (z. B. DNS-Round-Robin, Hardware-Lastausgleich). Unter http://www.onjava.com/pub/a/onjava/2001/09/26/load.html werden verschiedene Methoden für den Lastausgleich erörtert. Unabhängig von der gewählten Methode sollten Sie den Lastausgleich in Ihre Clusterkonfiguration einbinden.
JBoss-Cluster-Gruppen
JBoss-Cluster basieren auf dem Kommunikationsmodul JGroups. JGroups wird zusammen mit JBoss installiert (das Modul kann auch ohne JBoss verwendet werden). JGroups bietet Kommunikation innerhalb von Gruppen, die einen Eigennamen, eine Multicast-Adresse und einen Multicast-Port gemeinsam nutzen.
Bei der Installation eines geclusterten JBoss-Servers definiert JBoss zwei verschiedene JGroups-Gruppen, die zur Verwaltung des Clusters verwendet werden können. Eine Gruppe heißt DefaultPartition und ist in /deploy/cluster-service.xml definiert. Diese Cluster-Gruppe wird von JBoss zum Bereitstellen von Core-Services im Zusammenhang mit der Cluster-Gruppierung verwendet. JBoss definiert außerdem eine zweite Cluster-Gruppe namens Tomcat-Cluster. Diese Cluster-Gruppe ist in /deploy/tc-cluster-service.xml definiert und ermöglicht dem Tomcat-Server, der in JBoss ausgeführt wird, die Sitzungsreproduktion.
Die Identity Manager-Benutzeranwendung verwendet eine dritte Cluster-Gruppe. Diese Cluster-Gruppe nutzt einen UUID-Namen, um das Risiko von Konflikten mit anderen Cluster-Gruppen, die Benutzer möglicherweise zu ihren Servern hinzufügen, zu minimieren. Die Cluster-Gruppe heißt standardmäßig c373e901aba5e8ee9966444553544200. Dieses Cluster wird nicht durch eine JBoss-Servicedatei konfiguriert. Stattdessen befinden sich die Konfigurationseinstellungen in dem Verzeichnis und können anhand der Administrationsfunktionen der Benutzeranwendung konfiguriert werden. Wenn Sie mit dem JGroups- und JBoss-Clustering vertraut sind, können Sie die Clusterkonfiguration der Benutzeranwendung anhand dieser Schnittstelle anpassen. Änderungen der Clusterkonfiguration werden erst nach einem Neustart des entsprechenden Serverknotens wirksam.
Die Benutzeranwendungs-Cluster-Gruppe wird ausschließlich für die Koordination der Benutzeranwendungs-Cache-Speicher in einer geclusterten Umgebung verwendet. Sie ist unabhängig von den beiden JBoss-Cluster-Gruppen und es findet keinerlei Interaktion statt. Die Benutzeranwendungs-Cluster-Gruppe und die beiden JBoss-Gruppen verwenden standardmäßig unterschiedliche Gruppennamen, Multicast-Adressen und Multicast-Ports, sodass keine Neukonfiguration erforderlich ist.
Die Cluster-Gruppen-Einstellungen der Benutzeranwendung werden von jeder Identity Manager 3-Anwendung mit derselben Verzeichniskonfiguration gemeinsam genutzt. Die Option der lokalen Einstellung in der Administrationsoberfläche der Benutzeranwendung ermöglicht dem Administrator, einen Knoten aus einem Cluster zu entfernen oder die Zugehörigkeit der Server zu einem Cluster zu ändern. Sie können die Cluster-Gruppierung z. B. zunächst global deaktivieren und dann lokal für einen Teil der Server mit derselben Verzeichniskonfiguration aktivieren.
Application Farming
JBoss ermöglicht Ihnen die clusterübergreifende Implementierung im laufenden Betrieb („hot-deploy“), indem ein Anwendungs-EAR, -WAR oder -JAR in das Farm-Verzeichnis einer geclusterten JBoss-Instanz kopiert wird. Die Implementierung im laufenden Betrieb auf einem Computer führt dazu, dass diese Komponente automatisch auf allen Instanzen innerhalb des Clusters verteilt wird, während das Cluster ausgeführt wird.
Diese Form der Anwendungsimplementierung wird für die Version von JBoss Application Server (4.0.2), die zu dem Zeitpunkt, als dieses Dokument geschrieben wurde, im Benutzeranwendungsinstallationsprogramm enthalten war, nicht empfohlen, da noch ungelöste Probleme bestehen. Es werden jedoch die grundlegenden Schritte aufgeführt (siehe Implementieren der Benutzeranwendung mittels JBoss-Farming), die für eine erfolgreiche Implementierung der Benutzeranwendung unter Verwendung der JBoss-Farming-Technologie auszuführen sind, da nach der Veröffentlichung dieses Dokuments mit einer Verbesserung der Technologie gerechnet werden kann.
MySQL-Datenbank
Das Installationsprogramm der Benutzeranwendung installiert entweder den MySQL-Datenbankmanager und erstellt eine Datenbank, die mit der Benutzeranwendung verwendet werden kann, oder es verwendet eine vorhandene Oracle-, Microsoft SQL Server- oder MySQL-Datenbank. Die Datenbank ist für die Datenpersistenz verantwortlich. Alle Knoten im JBoss-Cluster müssen auf dieselbe Datenbankinstanz zugreifen. Die Benutzeranwendung verwendet Standard-JDBC-Aufrufe für den Zugriff auf und die Aktualisierung der Datenbank. Die Benutzeranwendung verwendet eine an den JNDI-Baum gebundene JDBC-Datenquelle zum Herstellen einer Verbindung mit der Datenbank. Wenn Sie mit dem Installationsprogramm der Benutzeranwendung ein JBoss-Cluster erstellen, wird die Datenquelle für Sie installiert. Wenn Sie das JBoss-Cluster manuell einrichten möchten, müssen Sie die Datenquellendatei (IDM-ds.xml) auf allen Knoten in Ihrem Cluster in das Implementierungsverzeichnis kopieren. Wenn Sie MySQL verwenden, müssen Sie auch den MySQL-JDBC-Treiber (mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar), der sich im JBoss-Verzeichnis /server/IDM/lib befindet, in das JBoss-Verzeichnis server/IDM/lib kopieren.
Protokollierung
Um die Protokollierung für Cluster zu aktivieren, müssen Sie die Konfigurationsdatei „log4j.xml“ im Verzeichnis \conf für die JBoss-Serverkonfiguration (z. B. \server\IDM\conf) bearbeiten, indem Sie am Ende der Datei bei einem ähnlichen Abschnitt wie diesem die Kommentarzeichen entfernen:
<!-- Clustering logging --> - <!-- Uncomment the following to redirect the org.jgroups and org.jboss.ha categories to a cluster.log file. <appender name="CLUSTER" class="org.jboss.logging.appender.RollingFileAppender"> <errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/> <param name="File" value="${jboss.server.home.dir}/log cluster.log"/> <param name="Append" value="false"/> <param name="MaxFileSize" value="500KB"/> <param name="MaxBackupIndex" value="1"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p [%c] %m%n"/> </layout> </appender> <category name="org.jgroups"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> <category name="org.jboss.ha"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> -->
Die Datei cluster.log wird im log-Verzeichnis für die JBoss-Serverkonfiguration gespeichert (z. B. \server\IDM\log).
2.4.2 Installieren der Benutzeranwendung auf einem JBoss-Cluster
Es wird empfohlen, die Benutzeranwendung mithilfe ihres Installationsprogramms auf jedem Knoten in einem Cluster zu installieren. Obwohl es nicht empfohlen wird, die Benutzeranwendung in einem Cluster mittels JBoss-Farming zu implementieren, beinhaltet dieser Abschnitt alternativ eine entsprechende Anleitung.
Verwendung des Installationsprogramms der Benutzeranwendung auf jedem Knoten im Cluster
Im Lieferumfang von JBoss sind drei einsatzbereite Serverkonfigurationen enthalten: minimal, default und all. Die Cluster-Gruppierung ist nur in der Konfiguration all aktiviert. In der Datei cluster-service.xml im Ordner /deploy wird die Konfiguration der standardmäßigen Cluster-Partition beschrieben. Wenn Sie bei der Installation der Benutzeranwendung angeben, dass die Anwendung in ein Cluster installiert werden soll, kopiert das Installationsprogramm die Konfiguration all, benennt die Kopie IDM (Standard - eine Änderung des Namens ist möglich) und installiert die Benutzeranwendung in dieser Konfiguration.
So installieren Sie die Benutzeranwendung mit dem Installationsprogramm der Benutzeranwendung auf jedem Knoten in einem Cluster:
-
Installieren Sie die Benutzeranwendung vollständig (MySQL, JBoss und die Benutzeranwendung) auf dem ersten JBoss-Knoten. Informationen zur Verwendung des Installationsprogramms der Benutzeranwendung finden Sie in der Identity Manager 3-Installationsanleitung.
- Wenn Sie MySQL als Datenbank für die Benutzeranwendung verwenden, erstellt das Installationsprogramm der Benutzeranwendung eine neue Installation von MySQL. Notieren Sie sich das von Ihnen festgelegte Kennwort für den „root“-Benutzer von MySQL. Sie benötigen diese Informationen bei der Installation der Benutzeranwendung auf den anderen Knoten im Cluster.
- Wählen Sie im Installationsprogramm für die IDM-Konfiguration die Option für das vollständige Clustering („clustering (all)“).
- Wählen Sie entsprechend Ihrer Umgebung weitere Installationsoptionen aus.
-
Wenn MySQL noch nicht läuft, starten Sie MySQL über die Datei start-mysql.bat im Verzeichnis /IDM/mysql.
HINWEIS:Unter Linux können Sie mithilfe des folgenden Shell-Befehls ermitteln, ob der MySQL-Daemon ausgeführt wird:
ps -A | grep mysqld
Wenn dieser Befehl mehrere Zeilen zurückgibt, die auf mysqld enden, ist der Daemon aktiv.
-
Starten Sie JBoss und die Benutzeranwendung über die Datei start-jboss.bat (Windows) oder start-jboss.sh (Linux) im Verzeichnis IDM.

-
Führen Sie auf jedem Knoten des JBoss-Clusters eine benutzerdefinierte Installation der Benutzeranwendung durch.
- Wählen Sie aus, dass nur die Benutzeranwendung installiert werden soll:
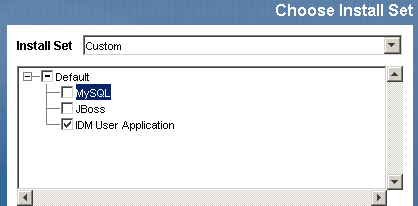
- Geben Sie die IP-Adresse oder den Hostnamen des Servers an, auf dem die Datenbank für die Benutzeranwendung installiert ist.
- Geben Sie den Benutzernamen und das Passwort für die Datenbank der Benutzeranwendung an. Bei MySQL lautet der Benutzername root und das Passwort ist das von Ihnen in Schritt 1 festgelegte Passwort.
- Wählen Sie im Installationsprogramm für die IDM-Konfiguration die Option für das vollständige Clustering („clustering (all)“).
- Wählen Sie entsprechend Ihrer Umgebung weitere Installationsoptionen aus.
-
Starten Sie jeden Knoten im JBoss-Cluster über die Datei start-jboss.bat (Windows) oder start-jboss.sh (Linux) im Verzeichnis IDM.
Implementieren der Benutzeranwendung mittels JBoss-Farming
Verwenden Sie JBoss-Farming nicht mit der JBoss-Version 4.0.2 oder früher, da andernfalls Probleme auftreten könnten (siehe http://jira.jboss.com/jira/browse/JBAS-1899). Es wird empfohlen, dass Sie die Benutzeranwendung mithilfe des Installationsprogramms der Benutzeranwendung auf jedem Knoten im Cluster installieren (siehe Verwendung des Installationsprogramms der Benutzeranwendung auf jedem Knoten im Cluster in diesem Kapitel). Wenn Sie die Benutzeranwendung trotzdem mittels Farming in einem JBoss-Cluster mit JBoss 4.0.3 oder höher implementieren möchten, führen Sie die folgenden Schritte aus.
HINWEIS:Diese Schritte sind nur für Kunden gedacht, die JBoss 4.0.3 auf eigene Gefahr und experimentell verwenden möchten. Die offiziell unterstützte Version ist 4.0.2.
So implementieren Sie die Benutzeranwendung mittels JBoss-Farming
-
Führen Sie eine benutzerdefinierte Installation der Benutzeranwendung auf einem der JBoss-Clusterknoten aus und wählen Sie die Benutzeranwendung und MySQL (falls Sie MySQL verwenden, andernfalls installieren Sie nur die Benutzeranwendung) für die Installation aus. Während der Installation können alle Cluster im Knoten ausgeführt werden. Der Knoten, auf dem Sie die Benutzeranwendung installieren, sollte jedoch der erste im Cluster gestartete Knoten sein.
-
Kopieren Sie die JDBC-Treiberdatei (bei der Verwendung von MySQL ist der JDBC-Treiber beispielsweise mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar) im Verzeichnis /server/IDM/lib in das entsprechende Verzeichnis auf jedem Knoten im Cluster.
-
Kopieren Sie die Datei cacerts aus dem Verzeichnis /lib/security der JRE, die gemeinsam mit der Benutzeranwendung installiert wurde, in das JRE-Verzeichnis /lib/security jedes Knotens im Cluster.
-
Verschieben Sie die Datei IDM.war und die Datenursprungsdatei IDM-ds.xml aus dem /deploy-Verzeichnis im Serverkonfigurationsverzeichnis in das /farm-Verzeichnis im Serverkonfigurationsverzeichnis. Beachten Sie, dass Sie die Dateien verschieben und nicht kopieren müssen. Belassen Sie die Originale nicht im /deploy-Verzeichnis.
-
Starten Sie die Datenbank für die Benutzeranwendung (wenn Sie die mitgelieferte MySQL-Datenbank verwenden, starten Sie MySQL über die Datei start-mysql.bat im Verzeichnis /IDM/mysql).
-
Starten Sie JBoss und die Benutzeranwendung über die Datei start-jboss.bat (Windows) oder start-jboss.sh (Linux) im Verzeichnis IDM des Knotens, in dem Sie die Benutzeranwendung und die Datenbank der Benutzeranwendung installiert haben.
-
Starten Sie die anderen Knoten im Cluster.
2.4.3 Konfigurieren des Cluster-Gruppen-Cachings der Benutzeranwendung
Benutzer, die mit der JGroups- und der JBoss-Cluster-Gruppierung vertraut sind, können die Konfiguration des Cluster-Gruppen-Cachings über die Administrationsschnittstelle der Benutzeranwendung ändern (siehe Schnitt 13.3.5, Cache-Einstellungen für Cluster). Änderungen der Clusterkonfiguration werden erst nach einem Neustart des entsprechenden Serverknotens wirksam.
2.4.4 Konfigurieren der Workflows für die Cluster-Gruppierung
Die Cluster-Gruppierung der Workflow-Engine arbeitet unabhängig vom Cache-Framework der Benutzeranwendung. Sie müssen mehrere Schritte ausführen, um sicherzustellen, dass die Workflow-Engine in einer Cluster-Umgebung ordnungsgemäß funktioniert.
- Alle Server im Cluster müssen auf dieselbe Datenbank verweisen. Wenn Sie die Benutzeranwendung wie empfohlen (siehe Verwendung des Installationsprogramms der Benutzeranwendung auf jedem Knoten im Cluster) auf dem Cluster installieren, geschieht dies während des Installationsvorgangs durch die Angabe der IP-Adresse bzw. des Hostnamens des Servers, auf dem die Datenbank für die Benutzeranwendung installiert ist. Wenn Sie die Benutzeranwendung mittels Farming auf den Cluster-Knoten implementieren (siehe Implementieren der Benutzeranwendung mittels JBoss-Farming), geschieht dies durch das Verschieben der Datenquellendatei (IDM-ds.xml) vom /deploy-Verzeichnis in das /farm-Verzeichnis auf dem Knoten, auf dem die Benutzeranwendung als erstes installiert wurde. Dadurch wird die Datenquelle auf allen Knoten im Cluster implementiert.
- Jeder Server im Cluster muss mit einer eindeutigen Engine-ID gestartet werden. Dies erfolgt durch die Anpassung der Systemeigenschaft com.novell.afw.wf.engine-id beim Start des Servers. Wenn Sie z. B. JBoss starten und der Workflow-Engine für diesen Server die Engine-ID ENGINE1 zuweisen möchten, verwenden Sie folgenden Befehl:
run.sh -Dcom.novell.afw.wf.engine-id=ENGINE1 (Linux)
run.bat -Dcom.novell.afw.wf.engine-id=ENGINE1 (Windows)
Sobald eine Instanz eines Workflow-Prozesses von einer auf einem bestimmten Server ausgeführten Workflow-Engine gestartet wird, kann sie nur auf diesem Server ausgeführt und beendet werden. Dadurch wird sichergestellt, dass der Workflow-Prozess sicher ausgeführt wird. Es wird jedoch kein Failover einer Prozessinstanz unterstützt. Wenn ein Server in einem Cluster abstürzt, wird die Prozessinstanz erst dann neu gestartet, wenn eine Engine mit derselben ID neu gestartet wird.
Wenn ein Servercomputer aufgrund von schwerwiegenden Hardware- oder Softwarefehlfunktionen nicht neu gestartet werden kann, können Sie den Anwendungsserver auf einem neuen Computer starten, indem Sie dieselbe Workflow-Engine-ID wie für den Computer mit dem nicht behebbaren Fehler verwenden. Da die Engine-ID ein logischer Name ist und nicht direkt dem physischen Computer zugeordnet ist, auf dem die Engine ausgeführt wurde, wird die unterbrochene Prozessinstanz auf dem neuen Computer erfolgreich abgeschlossen.
Prozessinstanzen gehören zu der Engine, die den Prozess gestartet hat. Ein Benutzer kann sich jedoch auf jeder Benutzeranwendung in einem Cluster anmelden und sich Prozessdetails anzeigen lassen, Prozesse zurückziehen oder ihm zugewiesene Aufgaben erledigen. Zurückgezogene Prozesse oder abgeschlossene Aufgaben auf einer Engine, zu der der entsprechende Prozess nicht gehört, erhalten den Status „Ausstehend“ und werden wieder ausgeführt, wenn sie von der zugehörigen Engine gefunden werden.