This section provides troubleshooting suggestions for typical NetWare server problems such as the following:
The NetWare operating system is very resilient, but errors can occur. Serious problems are usually accompanied by abend (abnormal end) messages. When an abend message appears, either NetWare or the CPU has detected a critical error condition and started the NetWare fault handler. NetWare uses abends to ensure the integrity of operating system data.
When a server abends, users might not be able to log in to the server, workstations might not be to read from or write to the server, and an abend message usually appears on the System Console or Logger screen of the server console. If the NetWare auto-recovery mechanism is enabled (default), NetWare might restart the server automatically or suspend the offending process, depending on the nature of the abend.
If there is no abend message on the console, no ABEND.LOG file in SYS:SYSTEM, and no number in brackets within the System Console prompt, but users still can't access the server, see Monitoring and Resolving Communication Problems. If there is no abend message but the console is frozen so that you cannot enter commands, see Server Console Hangs.
When the server abends, it displays an abend message similar to the following:
Abend: SERVER-5.xx-message_number message_stringADDITIONAL INFORMATION: message
The Additional Information section states the probable cause of the abend. It indicates where the problem occurred and gives the name of any NLM associated with the abend. This information helps you determine how to resolve the abend.
The abend message, along with additional information, is saved in the ABEND.LOG file on drive C:. As soon as the server is restarted, the ABEND.LOG file is moved to SYS:SYSTEM.
You can respond to the abend manually or have the server respond automatically.
When you respond manually, the server determines the nature of the abend and displays the appropriate response option on the screen, along with additional options for bringing down the server or executing a core dump. You must execute an option to respond to the abend.
When the server responds automatically, it executes the appropriate response without intervention.
IMPORTANT: Sometimes an abend (or a faulty NLM program) can cause the server console to stop functioning. In this case, the abend message is not displayed and you cannot enter commands at the console prompt.
After a server failure, we recommend turning the power off of the computer and restarting it rather than just exiting to the DOS prompt, C:\NWSERVER, and typing SERVER again.
The default method of responding to an abend is automatic. (See Responding to the Abend Automatically.)
To respond manually to abends, change the following SET parameter (Error Handling category) to the value shown:
AUTO RESTART AFTER ABEND = 0
This SET parameter controls what the server does after an abend. See the online help for a description of each value.
When an abend occurs, the server displays a short list of options appropriate to the nature of the abend. To respond to the abend, you must execute one of the options by typing the first letter of the option.
The following options could be displayed. Note that several of the options have the same first letter (such as R, S, or X). In a given abend situation, the option list will include only one option for any given first letter.
This option appears if the abend was software-detected--- that is, detected by the network operating system. It is important to save files, shut down the server, and try to solve the problem that caused the abend. Review the ABEND.LOG file to help determine the source of the problem.
When you execute this option, the server sends a message to users that the server is going down and advising them to save their files and log out. The server then stops the running process, updates the ABEND.LOG file, and attempts to shut down and restart the computer.
The amount of time before the server shuts down and restarts is determined by the SET parameter AUTO RESTART AFTER ABEND DELAY TIME. You can set this value from 2 to 60 minutes. The default is 2 minutes.
You can submit the ABEND.LOG file the the abend log database at Novell to help you troubleshoot the abend.
This option appears if the abend has detected a hardware problem. Shut down the server, fix the hardware, run diagnostics, and contact the harware manufacturer for additional assistance. When you execute this option, the server sends a message to the users that the server is going down and advising them to save their files and log out. The server then resumes the running process, updates the ABEND.LOG file, and attempts to shut down and restart the computer. The amount of time before the server shuts down and restarts is determined by the SET parameter AUTO RESTART AFTER ABEND DELAY TIME. You can set this value from 2 to 60 minutes.
This option appears if the abend was hardware-detected---that is, detected by the processor. All hardware-detected abends have the words processor exception in the abend message. These abends include page faults, protection faults, and invalid op codes stack overflows, double faults, etc. When this option is available, the server has determined that it cannot return the process to a safe state, but it does not need to shut down the server immediately to resolve the problem. You might still need to shut down the operating system and restart it at a later time. When you execute this option, the server suspends the currently running process and updates the ABEND.LOG file, but does not shut down the computer. Server performance might be poor, because a loaded NLM is probably malfunctioning. Read the Additional Information part of the abend message to learn which NLM might be causing the problem. At a convenient time, shut down the server and restart it. Examine the ABEND.LOG file for more information about the source of the problem. You can submit the ABEND.LOG file the the abend log database at Novell to help you troubleshoot the abend.
Like the previous option, this option appears if the abend was hardware-detected---that is, detected by the processor. All hardware-detected abends have the words processor exception in the abend message. These abends include page faults, protection faults, and invalid op codes, stack overflows, double faults, etc. When this option is listed, the server has determined that it can return the process to a safe state. When you execute this option, the server returns the running process to a safe state and updates the ABEND.LOG file, but it does not shut down the server. In most cases, the server completely recovers and no further action is necessary.
Execute this option to perform a core dump that can be examined to determine the cause of an abend. For information on core dumps, see Creating a Core Dump.
This option appears only if DOS has been removed. Execute this option if you want to restart the server. If DOS has been removed, the server will not create or update an ABEND.LOG file.
Execute this option if you want to shut down the server and exit to DOS. If you power off the server without first executing one of the S or R options to resolve the abend, the server will not update the ABEND.LOG file.
If the console has been secured, you must power it off and then back on to restart the server. If you power off the server without first executing one of the S or R options to resolve the abend, the server will not update the ABEND.LOG file.
When the server restarts, it moves the ABEND.LOG file from the DOS partition to the SYS:SYSTEM directory.
You can require the server to respond automatically to abends. Two automatic responses are possible.
AUTO RESTART AFTER ABEND = 1
DEVELOPER OPTION = OFF
Because these are the default values of the parameters, the default mode is to respond to abends automatically.
AUTO RESTART AFTER ABEND = 2 DEVELOPER OPTION = OFF
Use the following SET parameter to specify how long the server waits after an abend before attempting to shut down and restart the computer:
AUTO RESTART AFTER ABEND DELAY TIME = minutes
To set the parameter values, use the SET command or MONITOR at the server console or NetWare Remote Manager from a workstation.
The Developer Option parameter is in the Miscellaneous category.
The Auto Restart After Abend and Auto Restart After Abend Delay Time parameters are in the Error Handling category.
All parameters can be set in the STARTUP.NCF file.
Because the server responds to the abend automatically, you might not know when an abend has occurred. Therefore, you should periodically check the ABEND.LOG file or the Profiling and Debug Information screen in NetWare Remote Manager (look for Suspended by Abend Recovery status).
The ECB (event control block) counter is incremented when a device sends a packet to your NetWare server but no packet receive buffer is available. This mean a packet has been dropped by the server.
The server allocates more packet receive buffers after each incident until it reaches its maximum limit (Maximum Packet Receiver Buffer setting).
If you are using an EISA busmaster board (such as the NE3200TM board), you will probably need to increase both the minimum and maximum number of packet receive buffers.
For procedures on setting the Minimum Packet Receive Buffers and Maximum Packet Receive Buffers parameters, see SET > Communications Parameters in Utilities Reference.
No ECB Available Count messages can also indicate that the driver is not configured correctly or that the Topology Specific Module (TSM) and the Hardware Specific Module (HSM) are incompatible. This value is maintained by the TSM.NLM program.
If the ECB count is increasing and all the packet receive buffers are in use, take a coredump (see Creating a Core Dump) and contact Novell technical support.
To diagnose slow server response problems, identify whether the following conditions exist:
To resolve slow server response problems, perform the following actions:
To check the health of these values, use NetWare Remote Manager. Click the Health Monitor link in the navigation frame. Click the links for the Allocated Server Processes, Available Server Processes, and Packet Receive Buffers on the Server Health Monitoring page. Packet receive buffers are used to transmit and receive packets. If the number of Pack Receive Buffers is increasing, the server operating system will be sluggish. If the number of Packet Receive Buffers reaches the maximum and no ECBs are available, the system will become very sluggish and might not recover. If the current server process are approaching the maximum, you should consider increasing the Maximum Server Processes SET parameter value. If you have only a few available server processes, your server is probably very busy. You might consider increasing the Minimum and Maximum Server Process SET Parameter. To change the values for these parameters, access NetWare Remote Manager. Click the Set Parameter link in the navigation frame. On the Set Parameter Categories page, click the following:
You can also use MONITOR or the SET commands at the server console. MIRROR STATUS
You can also set the Purge attribute on files you want to be purged.
If you are using more than one network board in the server, compare the boards' Total Packets Transmitted statistics. If one board is receiving most of the traffic, recable the network so that the boards have equal loads.
If the server console locks up so that you cannot enter commands, but there is no abend message on the System Console or Logger screen, follow these steps to troubleshoot the problem. If there is an abend message on the screen, see Resolving Abends.
Verify whether you can toggle among console screens.
If yes, the problem might be caused by high server utilization. See High Utilization Statistics. If no, continue with the following steps.
Verify whether the server console hangs when you unload a specific NLM.
If yes, the NLM is probably the source of the problem. Contact the NLM vendor.
Make sure you are using the latest disk and LAN drivers, BIOS, and firmware.
If not, update disk and LAN drivers. For information on NetWare drivers, see Keeping Your Servers Patched.
Verify whether the server console hangs after you mounted the last volume.
If yes, the network board might not be seated correctly or might not be configured correctly. Check the board and its configuration and correct any problems.
Verify whether you can you break into the debugger by pressing Shift+Shift+Alt+Esc on the system console keyboard.
If the console is locked, you can't toggle among screens and you can't enter the debugger, contact Novell Technical Support or your computer vendor to learn how to generate a nonmaskable interrupt to shut down the server.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology; search the Novell Knowledgebase; and contact a Novell Support Provider.
Network performance is a key concern for network administrators and for Novell as well. Unfortunately, sometimes there is confusion about performance indicators and what their statistics mean.
For example, the idea that processor utilization is the key performance indicator for NetWare is much too simple. Some network administrators are concerned when the CPU Utilization health status in NetWare Remote Manager or the Utilization value in MONITOR's General Information screen approaches 100%, on the assumption that the higher the percentage, the worse NetWare's performance is. This is entirely false.
Consider first what the Utilization value represents: the average of the server's total processing capacity that was used during the last second (update interval). The remainder of the capacity was spent in the idle loop process. In other words, it is an indication of how much of that time the processor had something to do. A high utilization value means that NetWare is using that percentage of the processor's capacity and wastes less time doing nothing.
Some processes make efficient use of the processor and as a result might cause 100% utilization. This type of utilization is entirely appropriate. Most of the time, when utilization moves up to 100%, it means that the thread is using the processor efficiently. It might stay at 100% for a couple of minutes; this is normal.
It is not normal, however, when the utilization is at 100% for 15 to 20 minutes or more, when connections are dropped, or when server performance deteriorates noticeably. High utilization with these conditions indicates a problem. If you're not seeing these conditions, your utilization might be normal, even when it's at 100%.
How do you know what is normal for your server? You will recognize problems if you "baseline" your server. Know what is normal and know the difference between a cosmetic problem and a true performance problem. (You can test for a cosmetic problem by loading or unloading any NLM; this will cause the processor information to be recalculated.)
Before troubleshooting high utilization problems, make sure that you have followed the steps in Using a Troubleshooting Methodology. Check the Novell Support Connection Web site for NetWare patches or updated NLM programs. Available patches will contain fixes for reported high utilization problems related to the actual code of the operating system and eDirectory.
However, a number of high utilization conditions can still result from problems with configuration, levels of NLM programs, and tuning issues.
One of the first things you might want to do is discover the NLM program and threads that are using the CPU. To do this, complete the following steps:
Access NetWare Remote Manager.
Click the Profile/Debug link in the navigation frame.
Click the Profile CPU Execution by NLM link.
Note the parent NLM program and threads that are taking the longest execution time.
If possible, unload the offending NLM program to see if the problem disappears.
You can also use the following list of issues to help you resolve problems.
The items in the list are categorized, but are otherwise in no particular order. The list represents the collective experience of Novell Support representatives. We recommend that you review each item, using each to carefully analyze your system. Except for problems new to NetWare 6, you will be able to resolve the problem on your own in almost every case.
Server resources. Server resources can be divided into LAN, disk, and processor resources. LAN and disk resources are the number of buffers available. Processor resources are the number of service processes available. When a network packet arrives or when a disk read or write is performed, a buffer should be available to hold the data until a service process is available to service it. Running low on either buffers or service processes for even a brief period can cause high utilization on the server and delay for the users.
To understand how server parameters work together to control the allocation of server resources, see Monitoring Allocated Services.
For the procedure to configure the allocation of packet receive buffers (communication buffers), see Increasing Maximum and Minimum Packet Receive Buffers in the Server Communications Administration Guide and SET > Communications Parameters in Utilities Reference for parameter descriptions.
For information on controlling the allocation of directory cache, see Tuning Directory Cache for the Traditional File System in the Server Memory Administration Guide and SET > Directory Caching Parameters for the Traditional File System in Utilities Reference.
For setting up and tunning cache buffers in the NSS file system, see Setting the Cache Buffers in the Novell Storage Services Administration Guide.
For parameter descriptions, see also the service processes parameters in SET > Miscellaneous Parameters in Utilities Reference.
We suggest that the server parameters in the following table be set as indicated to avoid running low on server resources. This is especially important if you have 100 or more users. To change the following parameters, you can use NetWare Remote Manager at the workstation or SET or MONITOR at the server console.
In NetWare Remote Manager, click the Set Parameters link in the navigation frame > Category > current value for parameter. Enter the new value and then click OK.
In MONITOR, from the Available Options menu, select server Parameters > Category > current_value_for_parameter and then press Enter. Enter the new value, and then do applicable action.
Processor hog. Determine whether one thread is hogging the processor. In NetWare Remote Manager, click Profile / Debug link in the navigation frame. View the data in the Execution Profile Data by Thread table. In MONITOR, from the Available Options menu, select Kernel Options > Threads, and then press Enter. You can set the CPU Hog Timeout Amount to a value lower than the default. Specify the amount of time in seconds to wait before terminating a thread that has not relinquished control of the processor. See SET > Miscellaneous Parameters in Utilities Reference. IMPORTANT: Use caution when changing this value. You must understand the impact of what you are changing.
Drivers. See Keeping Your Servers Patched. For a brief explanation of NetWare Peripheral Architecture (NWPA), see Drivers for Host Adapters and Storage Devices in NetWare Server Disks and Storage Devices Administration Guide.
Free blocks. When using the traditional file system, adequate free blocks are essential. A free block is a disk block that has no salvageable files stored there. A file that has been both deleted and purged becomes free space. Maintain a minimum of 1000 free blocks on each NetWare volume that has suballocation enabled. Suballocation, normally a low priority process, uses free blocks to perform its function. When free blocks are low, suballocation can go into an "aggressive" mode. Maintaining over 1000 free blocks will usually avoid this problem. To check how many free blocks you have on a volume, do either of the following:
If there are not at least 1000 free blocks on the volume, access NetWare Remote Manager, click Volumes in the navigation frame, click the Volume Information icon for the applicable volume, and then click the Purge Deleted Files button. This removes all deleted files from the directories and subdirectories and increases your free disk space. If you have applications that create large numbers of temporary, files you might want to set the P (Purge) flag on the directories where these files are stored. Every temporary file that is created will be put on the deleted file list. These files are kept on the disk until PURGE is run. You could also run SET Immediate Purge of Deleted Files=On at the System Console prompt. Suballocation. The traditional file system uses a disk block size of 64 KB. It is very important to monitor the disk space. Novell Technical Support recommends keeping 10% to 20% of the volume space free to avoid suballocation problems. Suballocation does not have any server parameters to adjust. To view disk space usage with NetWare Remote Manager, click the Health Monitor link in the navigation frame and then the Available Disk Space link on the Server Health Monitoring page. Print the Volume Information page for your records. Compression. When using compression in the NSS file system, see the following procedures, Other NSS Commands in the Novell Storage Services Administration Guide. When using compression with the Traditional file system, it is essential to have the server patched. Because it takes processor cycles to compress and decompress files, compression needs to be monitored carefully to avoid utilization problems. The default SET File Parameters for the Traditional File System for compression takes this into consideration. For example, file compression is set by default to occur during off-hours or periods of low server usage. Make sure that change have not been made that are causing high utilization problems. File decompression occurs on the fly. However, a very large file, such as 100 MB, can take a noticeable amount of time even with a Pentium* processor. SET Deleted Files Compression Option=2 causes the immediate compression of files that have been deleted. This can cause high utilization because the processor immediately compresses files upon their deletion. Directories that are flagged IC (Immediate Compression) can cause excessive decompression during work hours. Users with disk space restrictions might flag their home directories to IC in an attempt to save disk space. This can affect server performance. To ensure that frequently used files are not compressed, you can specify an appropriate value for the SET Days Untouched Before Compression parameter. To proactively eliminate compression as a possible problem, use SET Enable File Compression=Off parameter (Common File System category). This will cause files to be queued for compression but the files will not be compressed. However, accessing compressed files causes them to be decompressed.
Insufficient RAM. Memory resources are critical in a server environment.
To view buffer cache statistics for the NSS file system, enter the following command at the System Console prompt:
NSS CACHESTATS
The best indicator for assessing server RAM in a traditional file system is displayed in the following ways:
The value of this field should be a minimum of 15 to 20 minutes. A number lower than this indicates that the server's memory resources might be low. Another good indicator, Long Term Cache Hits, is displayed on the same page or screen in either utility.
eDirectory partitions. We recommend having no more than three replicas of each partition in the tree. Efficient tree design is essential to avoid utilization problems. Because Novell® eDirectoryTM needs to maintain synchronization among all servers in the replica ring, the more replicas there are of any partition, the more traffic will be on the wire. Three replicas are enough to provide fault tolerance and to allow for eDirectory if a database were to become corrupt.
eDirectory synchronization. To test the possibility that eDirectory synchronization is the problem, turn off inbound and outbound synchronization for an hour by setting dstrace=!D60. After turning synchronization off, wait 5 to 15 minutes to allow the server to catch up with queued work. Cancel the test by setting dstrace=!E.
eDirectory errors. To test for other errors, run SET dstrace=On.
Hung connections. Check for them and clear them. See Clearing a Workstation Connection.
Client software. You can identify client problems by changing SET NCP SET parameter. For more information, see NCP Parameters in Utilities Reference. By setting these server parameters to On, the server displays a warning each time a bad packet is received at the server. The warning message also includes the MAC (Media Access Control) addresses of devices where the packets originated. These parameters are in the NCP category:
Update client software.
Cabling. If you have installed high-speed 100 MB network boards, you might need to upgrade your cabling, too.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology; review tips in TID 10011512 "Troubleshooting High Utilization"; search the Novell Knowledgebase for High Utilization; and contact a Novell Support Provider.
To resolve disk I/O, disk space, and mirroring problems, see the following sections:
To resolve a general disk I/O error on the server, try one or more of the following remedies:
If you have tried all the preceding suggestions without success, contact your Novell Support Provider or the drive manufacturer.
To resolve an insufficient disk space error, do one or more of the following:
When mirrored partitions become unsynchronized, they should resynchronize automatically. If partitions do not resynchronize, complete the following steps:
In ConsoleOne, browse and select the tree you want to manage, and then click the Partition Disk Management icon.
Enter the eDirectory tree and context and server information.
Click Properties > Media > Mirror > Resync.
If the partitions still do not resynchronize, you must re-create the mirrored set.
Determine which disk partition has the data you want to save and mirror.
Delete the other disk partitions.
Recreate new partitions in place of the ones you deleted.
Mirror the partition containing data to the new partitions.
For information about mirroring, see Creating a Partition in the Novell Storage Services Administration Guide.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology, search the Novell Knowledgebase, and contact a Novell Support Provider.
If partitions are very large, mirroring can sometimes take several hours to complete; this is normal. The following might help to speed the mirroring process:
For known problems with specific hard disks or drivers, contact the drive vendor to ask if there are ways to speed drive mirroring. For example, some drivers can be loaded with parameters that speed the mirroring process.
Most disk drives provide their own form of read-after-write verification; therefore, NetWare's read-after-write-verify feature is not needed and can increase the time required to mirror partitions.
IMPORTANT: Increasing the value too much can cause some disk controllers or drivers to fail. You must experiment to see if a larger value speeds the mirroring process.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology, search the Novell Knowledgebase, and contact a Novell Support Provider.
Sometimes, the mirroring process proceeds without error but stops at 99% completion. To troubleshoot the problem, do the following:
If there are faulty disk blocks, troubleshoot and replace the disk if necessary.
For known problems with specific hard disks or drivers, contact the drive vendor.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology, search the Novell Knowledgebase, and contact a Novell Support Provider.
To diagnose problems when disk errors occur while a Traditional volume is mounting, identify whether the following conditions exist:
To resolve problems when disk errors while a volume is mounting, do the following:
To troubleshoot different kinds of server memory problems, to resolve memory leaks, and to resolve memory problems by freeing memory, see the following sections:
Use the following steps to find the source of the problem.
Verify whether you are using the NetWare memory manager or an external memory manager. Does CONFIG.SYS or AUTOEXEC.BAT include a DOS=HIGH statement or commands to load memory managers or DOS device drivers? For example, is there a command to load HIMEM.SYS or EMM386.EXE? Both are memory managers.
Comment out these statements from CONFIG.SYS or delete CONFIG.SYS altogether. Comment out these statements from AUTOEXEC.BAT. (To comment out a command, type REM and a space at the beginning of the command line.)
If there is a memory manager in the server, NetWare relies upon the memory manager to determine the amount of available memory instead of registering the memory itself. Some memory managers in older computers cannot recognize more than 64 MB of memory. DOS device drivers take memory away from NetWare's memory pool.
Make sure Windows 95 is not being used to boot the server. Windows 95 autoloads memory managers.
Make sure the server BIOS is current.
An out-of-date BIOS might be reporting the wrong amount of memory. If a newer version is available, update the BIOS.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology, search the Novell Knowledgebase, and contact a Novell Support Provider.
A memory leak means that an NLM or set of NLM programs has requested memory from the server, but has not returned the memory when finished with it. Over time, the amount of available memory decreases until eventually the server generates memory error messages. The memory leak might be slow or fast depending on the amount of memory requested each time.
If you reboot the server, the memory is returned to the memory pool, and the low memory error messages stop temporarily, until the memory leak ties up enough memory to generate the error messages again.
To see if the server has a memory leak, restart the server and then monitor memory statistics (Total Cache Buffers) over time. When traffic hasn't increased and no new applications are installed on the server and the statistics change, use the following steps to find the source of the problem.
Load all the latest patches on the server.
Server patches are available from Novell's Support Web Site and other locations. See Applying Patches for a list of sources.
Restart the server to free memory and establish a baseline for memory use.
View the memory statistics for the module:
Access NetWare Remote Manager.
Click the List Modules in the navigation frame.
Sort the list for memory usage by clicking the Alloc Memory button.
Click the value link for allocated memory for each module name you suspect might be the source of the leak.
Under normal conditions, modules such as SERVER.NLM, NSS.NLM and DS.NLM are usually at the top of the list.
Print this page and use it as a the baseline as you monitor the module's memory use over time.
Repeat Step 3 for each NLM you suspect might be the source of a memory leak.
(Conditional) If the memory error messages occur again, repeat Step 3 to view the memory statistics for each suspected NLM. Note whether memory use increased substantially for any of the modules.
If there is a memory leak, one or more modules will show a large increase in the Bytes in Use value.
When you discover the source of the memory leak, contact the module vendor to tell them about the problem. If possible, update the module or remove the module from the server.
To free server memory temporarily (until you can add more memory to the server), do one or more of the following:
If you combine directories so that most directories have about 32 files, and then purge the deleted subdirectories and files, you will free up memory. WARNING: This is a destructive step that destroys all the extended file information. Before taking this step, try to free up enough memory so that the volume mounts and you can back up the data.
Have all users log out, and then unload all modules except the volume's disk drivers. Dismount any mounted volumes. To remove the name space, load VREPAIR, select Set VRepair Options and then select two options: Write All Directory and FAT Entries Out to Disk and Remove Name Space Support from the Volume. Then run VREPAIR > Repair a Volume on the volume that would not mount. (This setting uses a lot of disk space but increases the amount of memory available.)
To diagnose problems when memory errors while a volume is mounting, identify whether the following conditions exist:
To resolve problems when memory errors while a volume is mounting, perform the following actions or ensure that the following conditions exist:
If you combine directories so that most directories have about 32 files, and then purge the deleted subdirectories and files, you will free up memory.
If the percentage is below 20%, add more memory.
WARNING: This is a destructive step that destroys all the extended file information. Before taking this step, try to free up enough memory so that the volume mounts and you can back up the data.
Have all users log out, and then unload all modules except the server's disk drivers. Dismount any mounted volumes. To remove the name space, load VREPAIR, select Set VRepair Options and select two options: Write All Directory and FAT Entries Out to Disk and Remove Name Space Support from the Volume. Then on the volume that would not mount, run VREPAIR, select Repair a Volume.
Typical memory error messages include the following:
If any of these conditions exist, use the following steps to find the source of the problem:
Make sure the server is not loading a memory manager or a DOS device drivers.
Check the AUTOEXE.BAT and CONFIG.SYS files to make sure no memory managers, such as HIMEM.SYS or EMM386.EXE, are being loaded, and that there is no DOS=HIGH statement in either file. Make sure no DOS device drivers are being loaded.
Comment out these statements from CONFIG.SYS or delete CONFIG.SYS altogether. Comment out these statements from AUTOEXEC.BAT. (To comment out a command, type REM and a space at the beginning of the command line.)
If there is a memory manager in the server, NetWare relies upon the memory manager to determine the amount of available memory instead of registering the memory itself. Some memory managers cannot recognize more than 64 MB of memory. DOS device drivers take memory away from NetWare's memory pool.
Make sure Windows 95 is not being used to boot the server. Windows 95 autoloads memory managers.
Make sure the server BIOS is current.
An out-of-date BIOS might be reporting the wrong amount of memory. Update the BIOS if a newer version is available.
Verify that the setting for the Reserved Buffers Below 16 MB SET parameter (Memory category) is set at 300 or higher.
For older drivers, increase the value to 300 or higher, especially if there is a CD-ROM or tape device that needs memory below 16 MB.
Make sure memory is being registered automatically.
Manually registering memory can cause memory fragmentation. Some old system boards might require you to register memory manually, but the better solution is to upgrade to a newer board so that NetWare will register the memory automatically.
If memory has been registered manually, reboot the server to free memory and do not manually register memory again. Upgrade the system board if necessary.
Verify whether memory errors occur when a traditional volume is mounting.
If yes, the server might be low on memory.
To free memory temporarily, see Freeing Server Memory Temporarily. To solve the problem, add more RAM.
Verify whether the "LRU sitting time" (in NetWare Remote Manager or MONITOR), average is more than 15 minutes during peak work hours.
If no, the server might be low on memory.
To free memory temporarily, see Freeing Server Memory Temporarily. To use the LRU Sitting Time to tune memory, see Tuning File Cache in the Server Memory Administration Guide. To solve the problem, add more RAM.
Check for memory leaks.
Do the LRU Sitting Time and Long Term Cache Hits gradually decline over time, even when network traffic has not increased and no new applications have been installed on the server?
If yes, the server might have a memory leak. See Resolving Server Memory Leaks.
If the problem still occurs, follow the troubleshooting steps in Using a Troubleshooting Methodology, search the Novell Knowledgebase, and contact a Novell Support Provider.
To resolve a locked device error, try one or more of the following:
If you have tried all of the above without success, contact a Novell Support Provider or the drive manufacturer.
Event control block allocation system messages can occur when you first start the server or after the server has been running for some time.
These messages indicate that the server was unable to acquire sufficient packet receive buffers, usually called event control blocks (ECBs). Running out of ECBs is not a fatal condition. However, it can indicate either a LAN or server problem.
Servers that run for several days where high loads occur in peaks might exceed the set maximum number of ECBs, causing the system to generate ECB system messages.
If these situations are caused by occasional peaks in the memory demand, you should probably maintain your current maximum ECB allocation and allow the message to be generated at those times.
Otherwise, if your server memory load is very high and you receive frequent ECB allocation errors, try setting your maximum ECB allocation higher. Use the following SET command in the STARTUP.NCF file:
SET MAXIMUM PACKET RECEIVE BUFFERS=number
Memory allocated for ECBs cannot be used for other purposes.
The minimum number of buffers available for the server can also be set in the STARTUP.NCF file with the following command:
SET MINIMUM PACKET RECEIVE BUFFERS=number
To diagnose server console command problems, identify whether the following conditions exist:
To resolve server console command problems, do the following:
Shut down the server, if possible. If not, wait a few minutes after all users have logged out, and then reboot the server.
The most common conflict occurs when a network board is set to interrupt 4 and a printer is connected to the server's serial port, which also uses interrupt 4.
To diagnose keyboard locking problems when copying files from CD-ROM, identify whether the following conditions exist.
If you have a CD-ROM device that shares a SCSI bus with a disk subsystem containing volumes that network operating system installation files are copied to (typically volume SYS:), your keyboard might lock while loading drivers or copying files to the volume. The following figure shows possible configuration conflicts.
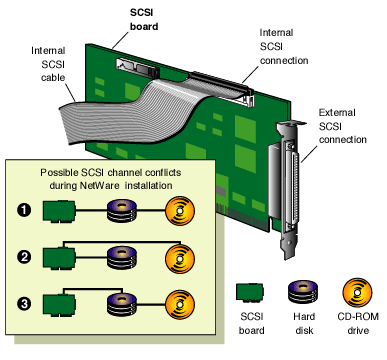
Remove the CD-ROM device drivers that you used to set up the CD-ROM drive as a DOS device from your CONFIG.SYS file. This will avoid possible conflicts when the Operating System CD is mounted as a NetWare volume.
To resolve keyboard locking problems when copying files from the CD, use the following procedure:
Press Alt+Esc until you are at the console prompt.
Enter DOWN.
Using a text editor, remove the CD-ROM device drivers from your CONFIG.SYS file.
Save the updated CONFIG.SYS file.
Using a text editor, remove any references to the CD-ROM drivers from your AUTOEXEC.BAT file.
Save the updated AUTOEXEC.BAT file.
Reboot the server by pressing Ctrl+Alt+Del.
(Conditional) If the server doesn't boot automatically from the AUTOEXEC.BAT file, change to the subdirectory where the SERVER.EXE file and other boot files are located (the default is C:\NWSERVER), and enter the following at the DOS prompt:
SERVER
(Conditional) If you are using ASPI device drivers (for example, for an Adaptec* controller), you need to enter one of the following commands:
AHAxxxx
where xxxx specifies the Adaptec board number
or
ASPICD
or
CDNASPI
At the console prompt, enter NWPA.
(Optional) At the console prompt, enter CD DEVICE LIST.
A list appears with numbers associated with all the devices on your network. Determine which number is the volume number.
At the console prompt, enter
CD9660.NSS
CD MOUNT volume_name|number
At the console prompt, enter NWCONFIG.