2.2 需求和设计分析阶段
利用在发现阶段创建的高级别路线图作为此分析阶段的起点。文档和 Designer 项目都需要添加技术和业务细节。这可产生用于实施 Identity Manager 解决方案的数据模型和高级别 Identity Manager 体系结构设计。
应将设计重心专门放在身份管理上,但是,也可以涉及到通常与资源管理目录(例如文件和打印)相关的许多元素。Identity Manager 将用户帐户同步到对操作系统的文件系统没有直接访问权的目录。例如,您可在 Active Directory 中具有用户帐户,但这并不会授予您对 Active Directory 服务器上文件系统的访问权。
使用在发现阶段收集的信息,回答以下示例问题,从而了解还需收集的其他信息。这可能要求与利害关系人再次进行面谈。
-
所使用的系统软件的版本是什么?
-
eDirectory 设计是否恰当?例如,Identity Manager 服务器是否包含正在同步的用户对象的主复本或读/写复本?如果不包含,则 eDirectory 设计不恰当。
-
所有系统中的数据质量是否合格?(如果数据达不到可用的质量,则可能无法根据需要实施业务策略。)例如,要同步的系统中可能存在用户的重复帐户,或各个系统的数据格式可能不一致。在同步信息前,必须先评估各个系统的数据。
-
环境是否需要数据处理?例如,用户的雇用日期格式在人力资源系统中只能是 2008/02/23,而身份库中的雇用日期是 02-23-2008。这要求处理数据以使同步能够进行。
Identity Manager 包含一种有助于简化数据分析和清理过程的工具。有关更多信息,请参见《Analyzer 4.0.1 for Identity Manager 管理指南》。
请查看部分 3.0, 技术准则中的信息以帮助做出有关环境的正确决策。
完成需求分析后,可为实施建立范围和项目计划,并确定是否需要执行任何先决活动。为避免出现代价高昂的失误,请尽量完整地收集信息和记录需求。以下是可能的需求的列表:
-
数据模型,显示所有系统、数据权威来源、事件、信息流、数据格式标准,以及 Identity Manager 中已连接系统和属性之间的映射关系。
-
解决方案的相应 Identity Manager 体系结构。
-
其他系统连接要求的细节。
-
数据验证和记录匹配的策略。
-
用于支持 Identity Manager 基础结构的目录设计。
在需求和设计评估过程中,应完成下列任务:
2.2.1 定义业务需求
在发现阶段中,您收集了贵组织的业务流程以及定义这些业务流程的业务需求。创建这些业务需求的列表,然后通过完成以下任务开始在 Designer 中映射这些流程:
-
创建业务需求的列表并确定受此流程影响的系统。例如,解雇一个员工的业务需求可能是,在解雇该员工的当天必须去除该员工的网络和电子邮件帐户访问权限。电子邮件系统和身份库受此解雇流程的影响。
-
建立流程、流程触发器和数据映射关系。
例如,如果某个流程中有事情发生,那么会触发其他哪些流程呢?
-
在应用程序之间映射数据流。Designer 允许您查看此信息。有关更多信息,请参见《Designer 4.0.1 for Identity Manager 4.0.1 管理指南》中的
管理数据流
。 -
认识从一种格式到另一种格式的数据转换,例如 2/25/2007 到 25 Feb 2007,并使用 Analyzer 更改数据。有关更多信息,请参见《Analyzer 4.0.1 for Identity Manager 管理指南》。
-
记录存在的数据依赖性。
如果更改了某个值,则务必要知道该值是否存在依赖性。 如果更改了特定的过程,则务必要知道该过程是否存在依赖性。
例如,选择人力资源系统中某个“临时”员工状态值,可能意味着 IT 部门需要在 eDirectory 中创建一个用户对象,该用户对象在特定的小时数内对网络的权限和访问权限将受到限制。
-
列出优先级。
并不是每一方的每个需求、愿望或期望都可以立即实现。 设计和部署供应系统的优先级有助于规划路线图。
将部署分阶段进行(使一部分部署早点实施,其余部分晚点实施),或使用分阶段进行的部署(基于组织中的人员分组)可能比较有利。
-
定义前提条件。
应该记录实施部署的特定阶段所需的先决条件。 这包括对需要与 Identity Manager 连接的已连接系统的访问权限。
-
确定权威数据源。
事先了解系统管理员和经理认为属于他们的信息项目,有助于获取各方的认可并让他们保持认可。
例如,帐户管理员可能需要为员工授予特定文件和目录访问权限的所有权。 在帐户系统中实施本地受托者指派可以达到此目的。
定义业务需求后,请转到部分 2.2.2, 分析业务流程。
2.2.2 分析业务流程
完成业务需求的分析后,您需要收集更多信息以帮助您专注于 Identity Manager 解决方案。您需要与实际使用该应用程序或系统的重要人士面谈,如经理、管理员和员工。要解决的问题包括:
-
数据源于何处?
-
数据流向何处?
-
数据由何人负责?
-
谁拥有对数据所属业务功能的所有权?
-
需要联系何人更改数据?
-
更改数据牵涉到的各个方面有哪些?
-
数据处理(收集和/或编辑)的工作惯例是什么?
-
执行何种类型的操作?
-
使用什么方法保证数据的质量和完整性?
-
系统驻留在何处(在哪些服务器上,在哪些部门中)?
-
哪些过程不适用于自动处理?
例如,可以对人力资源的 PeopleSoft 系统管理员提出以下问题:
-
将哪些数据储存在 PeopleSoft 数据库中?
-
员工帐户的各种面板上显示哪些内容?
-
供应系统中必须反映哪些操作(例如添加、修改或删除)?
-
其中哪些是必需的? 哪些是可选的?
-
需要根据 PeopleSoft 中执行的操作触发哪些操作?
-
要忽略哪些操作/事件/行为?
-
如何转换数据,以及将其映射到 Identity Manager?
会见关键人可了解组织的其他区域,这样可以更清楚地展现整个过程。
收集所有此类信息后,即可为您的环境设计正确的企业数据模型。请转到部分 2.2.3, 设计企业数据模型以开始设计。
2.2.3 设计企业数据模型
定义业务流程后,可使用 Designer 开始设计反映当前业务流程的数据模型。
Designer 中的模型应该阐明数据的来源、要移至的位置以及不能移至的位置。它还应说明关键事件如何影响数据流。例如,图 2-2 显示数据来自 PeopleSoft,但没有数据会向后同步到 PeopleSoft。
图 2-2 通过 Designer 的数据流
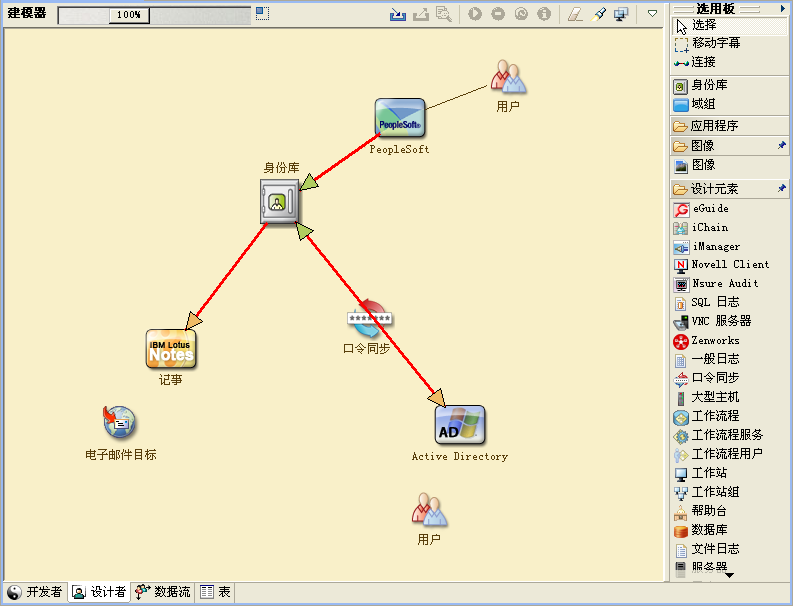
您还可能希望制作图表,用于演示建议的业务流程以及在该流程中实现自动供应的优势。
此模型的开发由回答类似以下的问题开始:
-
正在移动哪些类型的对象(用户、组等等)?
-
哪些是相关事件?
-
哪些特性需要同步?
-
在整个业务过程中,针对被管理的各种类型的对象储存了哪些数据?
-
同步是单向还是双向的?
-
哪个系统是哪些特性的权威来源?
考虑系统之间不同值的相互关系也很重要。
例如,PeopleSoft 中的员工状态字段可能有三个设置值:员工、合同工和实习生。但是,Active Directory 系统可能只有两个值:永久和临时。在此情况下,需要确定 PeopleSoft 中的“合同工”状态与 Active Directory 中的“永久”和“临时”值之间的关系。
此工作的重点应是了解每个目录系统、它们如何彼此相关,以及在整个系统中哪些对象和属性需要同步。设计完成后,下一步是创建概念检验。转到部分 2.3, 概念验证。