 |
| 
ここでは、NetWareサーバに関する次のような典型的な問題を解決するために役立つ、トラブルシューティングのヒントについて説明します。
NetWareオペレーティングシステムには高い回復能力がありますが、エラーが発生する場合もあります。重大な問題が発生すると、通常は、異常終了メッセージが表示されます。異常終了メッセージが表示されるのは、NetWareまたはCPUが重大なエラーを検出し、NetWare障害ハンドラを開始した場合です。NetWareでは、異常終了を使って、オペレーティングシステムのデータの整合性を維持しています。
サーバが異常終了すると、ユーザがサーバにログインできなくなったり、ワークステーションからサーバに対する書き出しや読み込みを実行できなくなったりする場合があります。また、異常終了メッセージが、サーバコンソールのシステムコンソールやログ画面に表示されます。NetWareの自動回復機能が有効になっている場合は(デフォルト)、異常終了の種類に応じて、サーバが自動的に再起動されるか、または、原因となっているプロセスが中断されます。
コンソールに異常終了メッセージが表示されず、SYS:SYSTEMにABEND.LOGファイルが存在せず、システムコンソールのプロンプト内の角カッコに数字が表示されていないにも関わらず、ユーザがサーバにアクセスできない場合は、「通信に関する問題を監視および解決する」を参照してください。異常終了メッセージは表示されないが、コンソールがフリーズしているためにコマンドを入力できない場合は、「サーバコンソールがハングする」を参照してください。
サーバが異常終了すると、次のような異常終了メッセージが表示されます。
Abend: SERVER-5.xx-message_number message_stringADDITIONAL INFORMATION: message
[Additional Information]セクションには、異常終了の原因として考えられる情報が表示されます。具体的には、問題が発生した場所と、異常終了に関係するNLMプログラムが表示されます。この情報は、異常終了の解決方法を判断するのに役立ちます。
異常終了メッセージは、この追加情報とともに、ドライブC:のABEND.LOGファイルに保存されます。サーバが再起動されると、直ちに、ABEND.LOGはSYS:SYSTEMに移動されます。
異常終了メッセージには、手動で応答することも、サーバが自動的に応答するように設定することもできます。
手動で応答する場合は、サーバが異常終了の種類を判別し、適切な応答オプションを表示します。サーバを停止する、またはコアダンプを作成するための追加オプションも同時に表示されます。異常終了に応答するには、いずれかのオプションを実行する必要があります。
サーバが自動的に応答する場合は、ユーザによる操作を必要とせずに、サーバが適切な応答オプションを実行します。
重要: 異常終了(または、問題のあるNLMプログラム)によって、サーバコンソールが機能しなくなる場合があります。その場合、異常終了メッセージは表示されず、コンソールプロンプトでコマンドを入力することはできません。
サーバ障害発生時には、DOSプロンプト(つまり、C:\NWSERVER)に移り、もう一度「SERVER」と入力するのではなく、コンピュータの電源を切り、再起動することをお勧めします。
異常終了に応答するデフォルトの方法は、自動です(「異常終了に自動的に応答する」を参照)。
異常終了に手動で応答するには、次のSETパラメータ(Error Handlingカテゴリ)を示されている値に変更します。
AUTO RESTART AFTER ABEND = 0
このSETパラメータは、異常終了後にサーバが実行する処理を制御します。各値の説明については、オンラインヘルプを参照してください。
異常終了が発生すると、サーバは、その異常終了の種類に応じて、適切なオプションのリストを表示します。異常終了に応答するには、オプションの先頭文字を入力して、いずれかのオプションを実行する必要があります。
次のようなオプションが表示されます。先頭文字が同じ(R、S、またはXなど)オプションがいくつもあることに注意してください。実際の異常終了発生時に表示されるリストには、先頭文字が同じオプションが2つ以上表示されることはありません。
このオプションは、異常終了がソフトウェア(つまり、ネットワークオペレーティングシステム)によって検出された場合に表示されます。ファイルを保存し、サーバをシャットダウンし、異常終了の原因となった問題を解決する必要があります。ABEND.LOGファイルを確認して、問題の発生原因を判別します。
このオプションを実行すると、サーバからユーザに、サーバが停止するので、ファイルを保存してログアウトするように要求するメッセージが送信されます。次に、サーバは実行中のプロセスを停止し、ABEND.LOGファイルを更新し、コンピュータをシャットダウンして再起動します。
サーバがシャットダウンして再起動するまでにかかる時間は、SETパラメータのAUTO RESTART AFTER ABEND DELAY TIMEによって決まります。この値は、2〜60分に設定できます。デフォルトは、2分です。
ABEND.LOGファイルは、異常終了のトラブルシューティングに役立てるために、Novellの異常終了ログデータベースに送信できます。
このオプションは、異常終了でハードウェアに関する問題が検出された場合に表示されます。サーバをシャットダウンし、ハードウェアを修復し、診断を実行します。次に、ハードウェアの製造元に連絡して、追加のサポートを受けてください。 このオプションを実行すると、サーバからユーザに、サーバが停止するので、ファイルを保存してログアウトするように要求するメッセージが送信されます。次に、サーバは実行中のプロセスを再開し、ABEND.LOGファイルを更新し、コンピュータをシャットダウンして再起動します。 サーバがシャットダウンして再起動するまでにかかる時間は、SETパラメータのAUTO RESTART AFTER ABEND DELAY TIMEによって決まります。この値は、2〜60分に設定できます。
このオプションは、異常終了がハードウェア(つまり、プロセッサ)によって検出された場合に表示されます。ハードウェアによって検出された異常終了の場合は、異常終了メッセージに「processor exception」という文字列が含まれます。 これらの異常終了には、ページ障害、保護障害、無効なopコードスタックオーバーフロー、二重障害などが含まれます。このオプションが使用可能である場合は、サーバが、プロセスを安全な状態に戻すことはできないが、問題を解決するために直ちにサーバをシャットダウンする必要はないと判断したことを示しています。ただし、オペレーティングシステムをシャットダウンし、後で再起動する必要がある場合があります。 このオプションを実行すると、サーバは、現在実行中のプロセスを中断し、ABEND.LOGファイルを更新しますが、コンピュータはシャットダウンしません。ロードされているNLMが正常に機能していない可能性が高いので、サーバのパフォーマンスは低くなる場合があります。 異常終了の[Additional Information]の部分を読んで、問題の原因となっている可能性があるNLMを調べます。用意ができたら、サーバをシャットダウンして再起動します。問題の発生原因の詳細については、ABEND.LOGファイルを参照してください。 ABEND.LOGファイルは、異常終了のトラブルシューティングに役立てるために、Novellの異常終了ログデータベースに送信できます。
前のオプションと同様に、このオプションは、異常終了がハードウェア(つまり、プロセッサ)によって検出された場合に表示されます。ハードウェアによって検出された異常終了の場合は、異常終了メッセージに「processor exception」という文字列が含まれます。 これらの異常終了には、ページ障害、保護障害、無効なopコードスタックオーバフロー、二重障害などが含まれます。このオプションが表示される場合は、サーバが、プロセスを安全な状態に戻すことができると判断したことを示しています。 このオプションを実行すると、サーバは、実行中のプロセスを安全な状態に戻し、ABEND.LOGファイルを更新しますが、サーバ自体はシャットダウンしません。ほとんどの場合、サーバは完全に回復し、追加の操作は必要ありません。
このオプションは、異常終了の原因を判別するために、コアダンプを作成して調べるときに使用します。コアダンプについては、「コアダンプを作成する」を参照してください。
このオプションが表示されるのは、DOSが削除されている場合だけです。このオプションは、サーバを再起動する場合に実行します。 DOSが削除されている場合、サーバは、ABEND.LOGファイルの作成や更新は行いません。
このオプションは、サーバをシャットダウンし、DOSに移る場合に実行します。[S]または[R]のいずれかのオプションを実行して異常終了を解決せずにサーバの電源を切った場合、サーバは、ABEND.LOGファイルを更新しません。
コンソールの安全を確認したら、電源を切り、電源を入れ直してサーバを再起動します。[S]または[R]のいずれかのオプションを実行して異常終了を解決せずにサーバの電源を切った場合、サーバは、ABEND.LOGファイルを更新しません。
サーバが再起動すると、ABEND.LOGがDOSパーティションからSYS:SYSTEMディレクトリに移動します。
異常終了に、サーバが自動的に応答するように設定できます。2種類の自動応答を使用できます。
AUTO RESTART AFTER ABEND = 1
DEVELOPER OPTION = OFF
これらの値はいずれも、パラメータのデフォルト値です。つまり、異常終了に対する応答のデフォルトモードは、自動です。
AUTO RESTART AFTER ABEND = 2 DEVELOPER OPTION = OFF
次に示すSETパラメータを使って、異常終了後に、サーバがコンピュータをシャットダウンして再起動するまでの、サーバの待機時間を指定します。
AUTO RESTART AFTER ABEND DELAY TIME = minutes
パラメータ値を設定するには、サーバコンソールでSETコマンドまたはMONITORを使用するか、またはワークステーションでNetWare Remote Managerを使用します。
Developer Optionパラメータは、Miscellaneousカテゴリにあります。
Auto Restart After AbendパラメータとAuto Restart After Abend Delay Timeパラメータは、Error Handlingカテゴリにあります。
すべてのパラメータは、STARTUP.NCFファイルで設定できます。
サーバが異常終了に自動的に応答するので、異常終了がいつ発生したのかがわからない場合があります。したがって、定期的にABEND.LOGファイルやNetWare Remote Managerの[Profiling and Debug Information]画面([Suspended by Abend Recovery]ステータスを参照)を確認する必要があります。
ECB (イベント制御ブロック)カウンタの値は、デバイスがNetWareサーバにパケットを送信する場合、パケット受信バッファが使用できないときに増加します。これは、サーバがパケットを受信できなかったことを示します。
サーバは、上限値(最大パケット受信バッファの設定)に達するまで、各事項の後に追加のパケット受信バッファを割り当てます。
EISAバスマスタボード(NE3200TMボードなど)を使用している場合は、パケット受信バッファの最小数と最大数の両方を大きくする必要があります。
Minimum Packet Receive BuffersパラメータとMaximum Packet Receive Buffersパラメータの設定手順については、『Utilities Reference』の「SET」の「Communications Parameters」を参照してください。
「利用可能なECBカウントがありません」というメッセージが表示される場合は、ドライバが正しく設定されていないこと、またはTSM (Topology Specific Module)とHSM (Hardware Specific Module)に互換性がないことを示している場合もあります。この値は、TSM.NLMプログラムによって管理されます。
ECBカウントが増加しており、すべてのパケット受信バッファが使用中である場合は、コアダンプを作成し(「コアダンプを作成する」を参照)、Novellテクニカルサポートに連絡してください。
サーバの応答が遅い問題を診断するには、次の条件が該当するかどうかを確認します。
サーバの応答が遅い問題を解決するには、次の操作を実行します。
これらの値が正常であるかどうかを確認するには、NetWare Remote Managerを使用します。ナビゲーションフレームの[Health Monitor]リンクをクリックします。[Server Health Monitoring]ページで、[Allocated Server Processes]、[Available Server Processes]、および[Packet Receive Buffers]リンクをクリックします。 パケット受信バッファは、パケットの送受信に使われます。パケット受信バッファの数が増加している場合、サーバオペレーティングシステムは遅くなります。パケット受信バッファの数が最大値に達し、使用可能なECBがない場合、システムは非常に遅くなり、回復しないこともあります。 現在のサーバ処理の数が最大値に近づいている場合は、Maximum Server Processes SETパラメータ値を大きくすることを検討する必要があります。使用可能なサーバ処理の数が少ない場合は、サーバの利用率が非常に高くなる可能性があります。Minimum Server ProcessとMaximum Server ProcessのSETパラメータ値を大きくすることを検討します。 これらのパラメータの値を変更するには、NetWare Remote Managerにアクセスします。ナビゲーションフレームの[Set Parameter]リンクをクリックします。[Set Parameter Categories]ページで、次の順にクリックします。
または、サーバコンソールで、MONITORまたはSETコマンドを実行することもできます。 MIRROR STATUS
または、パージするファイルのPurge属性を設定することもできます。
サーバで複数のネットワークボードを使用している場合は、ボードの[Total Packets Transmitted]統計情報を比較します。いずれかのボードがほとんどのトラフィックを受信している場合は、すべてのボードの負荷が等しくなるように、ネットワークのケーブル接続を変更します。
サーバコンソールがロックされているため、コマンドは入力できないが、システムコンソールやログ画面に異常終了メッセージが表示されない場合は、次の手順を実行して問題を解決します。画面に異常終了メッセージが表示される場合は、「異常終了を解決する」を参照してください。
コンソール画面を切り替えられるかどうかを検証します。
切り替えられる場合、問題の原因は、サーバの高利用率である可能性があります。「高利用率統計情報」を参照してください。切り替えられない場合は、次の手順に進みます。
特定のNLMをアンロードしたときに、サーバコンソールがハングするかどうかを検証します。
ハングする場合は、NLMがおそらく問題の原因です。NLMのベンダに連絡してください。
最新のディスクおよびLANドライバ、BIOS、およびファームウェアを使用していることを確認します。
最新でない場合は、ディスクおよびLANドライバを更新します。NetWareドライバについては、「サーバにパッチを適用する」を参照してください。
最後のボリュームをマウントした後に、サーバコンソールがハングするかどうかを検証します。
ハングする場合は、ネットワークボードが正しく装着されていない、または、正しく設定されていない可能性があります。ボードとその設定を確認し、問題があれば修正します。
システムコンソールキーボードで<Shift>+<Shift>+<Alt>+<Esc>を押すことによって、デバッガを起動できるかどうかを検証します。
コンソールがロックされており、画面を切り替えたり、デバッガを起動したりすることができない場合は、Novellテクニカルサポートまたはコンピュータのベンダに連絡し、サーバをシャットダウンするためにマスクできない割り込みを行う方法を確認してください。
それでも問題が発生する場合は、トラブルシューティングの使用のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
ネットワークパフォーマンスは、ネットワーク管理者だけでなく、Novellにとっても重要な問題です。パフォーマンスの指標と、その統計情報の意味について混乱が生じる場合があります。
たとえば、プロセッサ利用率が、NetWareの最も重要なパフォーマンスの指標であると考えるのは単純すぎます。ネットワーク管理者によっては、この利用率が高いほど、NetWareのパフォーマンスが低いと仮定し、NetWare Remote Managerの[CPU Utilization]ヘルスステータスや、MONITORの[General Information]画面に表示される[Utilization]の値が100%近くになると、問題があると判断します。このように考えるのは完全な誤りです。
まず、[Utilization]の値が何を表しているかを考えてください。この値は、直前の1秒間(更新間隔)に使用された、サーバの合計処理能力の平均です。それ以外の処理能力は、アイドルループプロセスに使用されたことになります。つまり、この値は、プロセッサが実際に処理を行っていた時間を示しています。利用率が高い場合は、NetWareが、その利用率に相当するだけプロセッサ能力を活用しており、アイドル状態でいる時間が短いことを意味します。
プロセスによっては、プロセッサを効率的に使用し、その結果、利用率が100%に達する場合があります。このような利用率は、正常です。ほとんどの場合、利用率が100%に達したときは、スレッドがプロセッサを効率的に使用していることを意味します。値が100%の状態は数分間継続する場合がありますが、これは正常です。
しかし、利用率が100%の状態が15〜20分以上継続する、接続が使用できなくなる、またはサーバパフォーマンスが著しく低下する場合、それは正常ではありません。これらの条件が該当する場合の高利用率は、問題があることを示しています。これらの条件が該当しない場合は、利用率が100%であったとしても、正常である可能性があります。
サーバにとって、どのような状態が正常なのかという点について考えてみます。サーバの「ベースライン」を識別すると、問題が認識しやすくなります。何が正常であるかを知り、表面的な問題と、本質的なパフォーマンスに関する問題を区別します(表面的な問題をテストするには、任意のNLMをロードまたはアンロードして、プロセッサ情報が再計算されるようにします)。
高利用率に関する問題を解決する前に、トラブルシューティングの使用の手順を実行してください。NetWareのパッチや更新されたNLMプログラムについては、NovellサポートのWebサイトを参照してください。利用可能なパッチには、オペレーティングシステムおよびeDirectoryの実際のコードに起因する、高利用率に関する既知の問題に対する修正プログラムが含まれています。
ただし、パッチを適用しても、設定、NLMプログラムのレベル、および調整に関する問題が原因で、数多くの高利用率の状況が発生する可能性があります。
まず最初に、CPUを使用しているNLMプログラムおよびスレッドを調べます。この操作を行うには、次の操作を実行します。
NetWare Remote Managerにアクセスします。
ナビゲーションフレームの[Profile/Debug]リンクをクリックします。
[Profile CPU Execution by NLM]リンクをクリックします。
実行時間が最も長いスレッドおよびペアレントNLMプログラムを確認します。
可能である場合は、そのNLMプログラムをアンロードして、問題が解決されるかどうかを確認します。
問題を解決するには、次に示す問題について検討することもできます。
リストの項目は、分類されている点を除き、順不同です。リストは、Novellサポート担当者の共通の経験を示しています。各項目を確認し、システムの分析に利用することをお勧めします。NetWare 6に関する新しい問題を除き、ほとんどの問題を、サポートの手を借りずに解決できます。
サーバリソース。 サーバリソースは、LAN、ディスク、およびプロセッサリソースに分類できます。LANおよびディスクリソースとは、使用可能なバッファ数のことです。プロセッサリソースとは、使用可能なサービスプロセス数のことです。ネットワークパケットが届く、またはディスクの読み込みや書き出しが実行されると、それを処理するためのサービスプロセスが使用可能になるまでデータを保持する、使用可能なバッファが必要になります。バッファまたはサービスプロセスが短時間不足しているだけでも、サーバの利用率が高くなり、ユーザに対する応答が遅くなります。
サーバパラメータの相互作用によって、サーバリソースの割り当てを制御する方法を理解するには、「割り当てられたサービスを監視する」を参照してください。
パケット受信バッファ(通信バッファ)の設定手順については、『Server Communications Administration Guide』の「Increasing Maximum and Minimum Packet Receive Buffers」、パラメータの説明については、『Utilities Reference』の「SET」の「Communications Parameters」をそれぞれ参照してください。
ディレクトリキャッシュの割り当ての制御については、『Server Memory Administration Guide』の「Tuning Directory Cache for the Traditional File System」および『Utilities Reference』の「SET」の「Directory Caching Parameters for the Traditional File System」を参照してください。
NSSファイルシステムでキャッシュバッファの設定および調整を行うには、『Novell Storage Services管理ガイド』の「キャッシュバッファの設定」を参照してください。
パラメータの説明については、『Utilities Reference』の「SET」の「Miscellaneous Parameters」にあるサービスプロセスパラメータも参照してください。
サーバリソースの不足を防ぐために、次の表に示すサーバパラメータを、示されている値に設定してください。これは、ユーザが100人以上いる場合に、特に重要です。次のパラメータを変更するには、ワークステーションでNetWare Remote Managerを使用するか、または、サーバコンソールでSETまたはMONITORコマンドを使用します。
NetWare Remote Managerの場合は、ナビゲーションフレームの[Set Parameters]リンクをクリックし、[Category]>[current value for parameter]の順に選択します。新しい値を入力し、[OK]をクリックします。
MONITORの場合は、[Available Options]メニューで、[server Parameters]>[Category]>[current_value_for_parameter]の順にクリックして、<Enter>を押します。新しい値を入力し、適切な操作を行います。
プロセッサホッグ いずれかのスレッドが、プロセッサを大量に消費しているかどうかを判別します。NetWare Remote Managerの場合は、ナビゲーションフレームの[Profile/Debug]リンクをクリックします。[Execution Profile Data by Thread]テーブルで、データを確認します。 MONITORの場合は、[Available Options]メニューで、[Kernel Options]>[Threads]の順に選択し、<Enter>を押します。 CPU Hog Timeout Amountには、デフォルト値より小さい値を設定できます。プロセッサの制御を渡さないスレッドを終了するまでの待機時間を秒数で指定します。『Utilities Reference』の「SET 」の「Miscellaneous Parameters」を参照してください。 重要: この値を変更するときは注意してください。変更による影響について理解している必要があります。
ドライバ 「サーバにパッチを適用する」を参照してください。NWPA (NetWare Peripheral Architecture)の簡単な説明については、『NetWare Server Disks and Storage Devices Administration Guide』の「Drivers for Host Adapters and Storage Devices」を参照してください。
空きブロック 従来のファイルシステムを使用している場合は、適度な空きブロックが必要です。空きブロックとは、サルベージ可能なファイルが保存されていないディスクブロックのことです。ファイルが削除およびパージされると、その領域は空き領域になります。細分割り当てが有効になっているNetWareボリュームごとに、最低でも1000個の空きブロックを確保してください。 細分割り当ては、通常、優先順位の低いプロセスですが、その機能を実行するには、空きブロックが必要です。空きブロックが不足していると、細分割り当てがアグレッシブモードになります。1000個を超える空きブロックを確保しておけば、通常、この問題を防止できます。 ボリュームの空きブロック数を確認するには、次のいずれかを実行します。
ボリュームの空きブロック数が1000個未満である場合は、NetWare Remote Managerにアクセスし、ナビゲーションフレームの[Volumes]をクリックします。次に、目的のボリュームに対応する[Volume Information]アイコンをクリックし、[Purge Deleted Files]ボタンをクリックします。 この操作によって、すべての削除済みファイルが、ディレクトリおよびサブディレクトリからパージされ、空きディスク容量が増加します。 多数の一時ファイルを作成するアプリケーションがある場合は、それらのファイルの保存先ディレクトリのP (Purge)フラグを設定できます。作成される一時ファイルはすべて、削除済みファイルリストに登録されるようになります。これらのファイルは、PURGEを実行するまで、ディスク上に保持されます。または、システムコンソールのプロンプトで、SET Immediate Purge of Deleted Files=Onを実行することもできます。 細分割り当て 従来のファイルシステムのディスクブロックサイズは、64KBです。したがって、ディスク領域を監視することが重要になります。Novellテクニカルサポートでは、細分割り当てに関する問題を防ぐために、ボリュームの10〜20%を空き領域にすることをお勧めしています。細分割り当てでは、サーバパラメータを調整する必要はありません。 NetWare Remote Managerを使ってディスク使用状況を表示するには、ナビゲーションフレームの[Health Monitor]リンクをクリックし、[Server Health Monitoring]ページの[Available Disk Space]リンクをクリックします。記録として[Volume Information]ページを印刷します。 圧縮 NSSファイルシステムで圧縮を使用するときは、『Novell Storage Services管理ガイド』の「その他のNSSコマンド」を参照してください。 従来のファイルシステムで圧縮を使用するときは、サーバにパッチを適用する必要があります。ファイルの圧縮および圧縮解除を行うにはプロセッササイクルが必要なので、利用率に関する問題を避けるために、注意深く監視する必要があります。圧縮で使用するデフォルトのSETファイルパラメータ(File Parameters for the Traditional File System)では、この点が考慮されています。 たとえば、デフォルトでは、ファイル圧縮の実行は、サーバ利用率が低い時間帯に設定されます。高利用率に関する問題の原因となる変更が行われていないことを確認してください。 ファイル圧縮解除は、通常の実行時に行われます。ただし、サイズが100MBなどの大きいファイルを圧縮する場合は、Pentium*プロセッサを使用しても時間がかかることがあります。 SET Deleted Files Compression Option=2に設定すると、削除されたファイルは直ちに圧縮されます。プロセッサは、ファイルが削除されると、直ちに圧縮するので、利用率が高くなります。 IC (Immediate Compression)フラグが設定されているディレクトリでは、業務時間内に大量の圧縮解除が実行される場合があります。ディスク容量が制限されているユーザは、ディスク容量を節約するために、自分のホームディレクトリにICフラグを設定する場合があります。この操作によって、サーバパフォーマンスが影響を受ける場合があります。 頻繁に使用するファイルが圧縮されないようにするには、SET Days Untouched Before Compressionパラメータを適切な値に設定します。 潜在的な問題として圧縮を積極的に取り除くには、SET Enable File Compression=Offパラメータ(Common File Systemカテゴリ)を使用します。この操作によって、ファイルは圧縮のキューには登録されますが、圧縮されません。ただし、圧縮されたファイルにアクセスすると、それらのファイルは圧縮解除されます。
RAMの不足 サーバ環境では、メモリリソースは重要です。
NSSファイルシステムのバッファキャッシュ統計情報を参照するには、システムコンソールのプロンプトで、次のコマンドを入力します。
NSS CACHESTATS
従来のファイルシステムでサーバのRAMを評価するための最善の指標を表示するには、次の方法を使用します。
このフィールドの値は、最低でも15〜20分である必要があります。これより小さい値は、サーバのメモリリソースが不足している可能性を示しています。もう1つの便利な指標である[Long Term Cache Hits]は、各ユーティリティの同じページまたは画面に表示されます。
eDirectoryパーティション レプリカの数は、ツリー内のパーティションごとに3つ以下にすることをお勧めします。効率的なツリーを設計することは、利用率に関する問題を避けるために重要です。Novell(R) eDirectoryTMでは、レプリカリング内のすべてのサーバ間で同期を維持する必要があるので、パーティションのレプリカ数が多くなるほど、ネットワーク上のトラフィックが増加します。耐障害性を確保し、データベースが壊れた場合にeDirectoryが使用できるようにするには、レプリカは3つまでで十分です。
eDirectoryの同期 eDirectoryの同期が問題である可能性をテストするには、dstrace=!D60に設定して、着信同期と送信同期を1時間オフにします。 同期をオフにしたら、サーバがキューに登録されている処理を実行するまで、5〜15分待ちます。dstrace=!Eに設定して、テストをキャンセルします。
ハングした接続 該当する接続を確認して、切断します。「ワークステーション接続を解除する」を参照してください。
クライアントソフトウェア クライアントに関する問題は、SET NCP SETパラメータを変更することによって識別できます。詳細については、『Utilities Reference』の「NCP Parameters」を参照してください。 これらのサーバパラメータをOnに設定することによって、サーバは、不良パケットを受信するたびに、警告を表示するようになります。警告メッセージには、パケットの送信元デバイスのMAC (Media Access Control)アドレスも含まれています。 これらのパラメータはNCPカテゴリにあります。
クライアントソフトウェアを更新します。
ケーブリング 高速の100MBネットワークボードをインストールした場合は、ケーブリングもアップグレードする必要がある可能性があります。
それでも問題が発生する場合は、トラブルシューティングの使用のトラブルシューティング手順を実行してから、TID 10011512「Troubleshooting High Utilization」のヒントを参照します。その後、Novell Knowledgebaseで高利用率について検索してから、Novellサポートプロバイダに連絡してください。
ディスクI/O、ディスク容量、およびミラーリングに関する問題を解決するには、次のセクションを参照してください。
一般的なディスクI/Oエラーを解決するには、次の方法を1つ以上試してください。
これらすべての手順を実行しても問題を解決できない場合は、Novellサポートプロバイダまたはドライブの製造元に連絡してください。
ディスク容量不足に関するエラーを解決するには、次の手順を1つ以上実行します。
ミラーリングされたパーティションが同期していない場合は、自動的に再同期されるはずです。パーティションが同期していない場合は、次の操作を実行します。
ConsoleOneで、操作するツリーを選択して、[Partition Disk Management]アイコンをクリックします。
eDirectoryツリー、コンテキスト、およびサーバ情報を入力します。
[プロパティ]>[Media]>[Mirror]>[Resync]の順にクリックします。
この操作を実行しても、パーティションが再同期されない場合は、ミラーリングされたセットを再作成する必要があります。
保存およびミラーリングするデータが格納されているディスクパーティションを判別します。
それ以外のパーティションを削除します。
削除したパーティションの代わりの、新しいパーティションを作成します。
データが含まれているパーティションを、新しいパーティションにミラーリングします。
ミラーリングについては、『Novell Storage Services管理ガイド』の「パーティションの作成」を参照してください。
それでも問題が発生する場合は、「トラブルシューティングの使用」のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
パーティションのサイズが大きい場合は、ミラーリングが完了するのに数時間かかることがありますが、これは正常です。ミラーリング処理を高速化するには、次の点について確認します。
特定のハードディスクまたはドライバに関する既知の問題については、ドライバベンダに連絡して、ドライブのミラーリングを高速化する方法があるかどうかを確認してください。たとえば、ドライバによっては、ミラーリング処理を高速化するパラメータを指定してロードできます。
多くのディスクドライバは、独自のリードアフタライト検証機能を備えています。したがって、NetWareのリードアフタライト検証機能を使用しないことで、パーティションのミラーリングを高速化できます。
重要: 値を必要以上に大きくすると、ディスクコントローラやドライバで障害が発生する場合があります。値を大きくすることによって、ミラーリング処理が高速化されるかどうかを試す必要があります。
それでも問題が発生する場合は、「トラブルシューティングの使用」のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
ミラーリング処理が99%まで正常に完了した時点で、処理が停止する場合があります。問題を解決するには、次の操作を実行します。
問題のあるディスクブロックがある場合は、問題を解決し、必要に応じてディスクを交換します。
特定のハードディスクまたはドライバに関する既知の問題については、ドライバベンダに連絡してください。
それでも問題が発生する場合は、「トラブルシューティングの使用」のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
従来のボリュームのマウント中にディスクエラーが発生した場合、問題を診断するには、次の条件が該当するかどうかを確認します。
ボリュームのマウント中に発生したディスクエラーを解決するには、次の操作を実行します。
サーバメモリに関するさまざまな問題を解決する、メモリリークを解決する、およびメモリを解放することによってメモリに関する問題を解決するには、次のセクションを参照してください。
次の手順を実行して、問題の発生原因を探します。
NetWareのメモリマネージャと外部メモリマネージャのどちらを使用しているかを確認します。CONFIG.SYSまたはAUTOEXEC.BATに、メモリマネージャまたはDOSデバイスドライバをロードするためのDOS=HIGH文またはコマンドが含まれていますか。たとえば、HIMEM.SYSまたはEMM386.EXEをロードするためのコマンドがありますか。どちらもメモリマネージャです。
CONFIG.SYSでこれらの文をコメント化するか、または、CONFIG.SYS自体を削除します。AUTOEXEC.BATで、これらの文をコメント化します(コマンドをコメント化するには、コマンドラインの先頭に「REM」とスペースを入力します)。
サーバにメモリマネージャがある場合、NetWareは、メモリをNetWare自体で登録するのではなく、そのメモリマネージャを使って、使用可能メモリを判断します。古いコンピュータのメモリマネージャによっては、64MBを超えるメモリを認識できません。DOSデバイスドライバは、NetWareのメモリプールからメモリを取り込みます。
サーバを起動するためにWindows 95を使用していないことを確認します。Windows 95では、メモリマネージャが自動的にロードされます。
サーバBIOSが最新であることを確認します。
古いBIOSを使用している場合は、メモリの量が間違って報告されている可能性があります。新しいバージョンが取得可能な場合は、BIOSを更新します。
それでも問題が発生する場合は、「トラブルシューティングの使用」のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
メモリリークとは、NLM、またはNLMプログラムの集まりが、サーバのメモリを要求し、処理が完了した後でメモリを戻さない状態を意味します。時間の経過とともに、使用可能メモリは減少し、最終的には、サーバがメモリエラーメッセージを生成します。処理ごとに要求されるメモリ量に応じて、メモリリークの速度は異なります。
サーバを再起動すると、メモリはメモリプールに戻され、メモリリークによって、エラーメッセージが生成される量にメモリが減少するまで、メモリ不足のエラーメッセージは、一時的に表示されなくなります。
サーバでメモリリークが発生しているかどうかを確認するには、サーバを再起動し、メモリ統計情報([Total Cache Buffers])を監視します。トラフィックが増加しておらず、サーバに新しいアプリケーションがインストールされていないにも関わらず、統計情報が変化する場合は、次の手順を実行して、問題の発生原因を確認します。
サーバにすべての最新パッチをロードします。
サーバパッチは、NovellサポートのWebサイトなどで取得できます。取得先の一覧については、「パッチの適用」を参照してください。
サーバを再起動してメモリを解放し、メモリ使用状況のベースラインを確立します。
モジュールのメモリ統計情報を表示します。
メモリリークの発生原因として疑われるNLMごとに、ステップ: 3を繰り返します。
(状況によって実行)それでもメモリエラーメッセージが発生する場合は、ステップ: 3をもう一度実行して、発生原因として疑われるNLMごとにメモリ統計情報を表示します。いずれかのモジュールで、メモリの使用量が著しく増加したかどうかを確認します。
メモリリークがある場合は、1つ以上のモジュールで、[Bytes in Use]の値が大幅に増加します。
メモリリークの発生原因を発見したら、モジュールベンダに連絡して、問題を報告します。可能である場合は、モジュールを更新するか、またはサーバから削除します。
サーバメモリを一時的に(サーバにメモリを追加できるまで)解放するには、次の手順を1つ以上実行します。
ほとんどのサブディレクトリに32個のファイルが含まれるようにディレクトリを統合して整理し、削除したサブディレクトリおよびファイルをパージすると、メモリが解放されます。 警告: この手順を実行すると、すべての拡張ファイル情報が破壊されます。この手順を実行する前に、ボリュームをマウントして、データをバックアップできるだけのメモリを解放してください。
すべてのユーザにログアウトするように指示し、ボリュームのディスクドライバを除く、すべてのモジュールをアンロードします。マウントされているすべてのボリュームをマウント解除します。 ネームスペースを削除するには、VREPAIRをロードし、[Set VRepair Options]を選択します。次に、[Write All Directory and FAT Entries Out to Disk]と[Remove Name Space Support from the Volume]の2つのオプションを選択します。次に、マウントできないボリュームに対して、VREPAIRを実行し、[Repair a Volume]を選択します。 (この設定を使用すると、多くのディスク領域が必要になりますが、使用可能メモリが増加します)
ボリュームのマウント中にメモリエラーが発生した場合、問題を診断するには、次の条件が該当するかどうかを確認します。
ボリュームのマウント中に発生したメモリエラーを解決するには、次の操作を実行するか、または次の条件が該当するかどうかを確認します。
ほとんどのサブディレクトリに32個のファイルが含まれるようにディレクトリを統合して整理し、削除したサブディレクトリおよびファイルをパージすると、メモリが解放されます。
パーセンテージが20%より低い場合は、メモリを追加します。
警告: この手順を実行すると、すべての拡張ファイル情報が破壊されます。この手順を実行する前に、ボリュームをマウントして、データをバックアップできるだけのメモリを解放してください。
すべてのユーザにログアウトするように指示し、サーバのディスクドライバを除く、すべてのモジュールをアンロードします。マウントされているすべてのボリュームをマウント解除します。 ネームスペースを削除するには、VREPAIRをロードし、[Set VRepair Options]を選択します。次に、[Write All Directory and FAT Entries Out to Disk]と[Remove Name Space Support from the Volume]の2つのオプションを選択します。次に、マウントできないボリュームに対して、VREPAIRを実行し、[Repair a Volume]を選択します。
典型的なメモリエラーメッセージの例を次に示します。
前のいずれかの条件が該当する場合は、次の手順を実行して、問題の発生原因を探します。
サーバが、メモリマネージャやDOSデバイスドライバをロードしていないことを確認します。
AUTOEXE.BATおよびCONFIG.SYSファイルをチェックして、HIMEM.SYSやEMM386.EXEなどのメモリマネージャがロードされていないこと、およびDOS=HIGH文がないことを確認します。DOSデバイスドライバがロードされていないことを確認します。
CONFIG.SYSでこれらの文をコメント化するか、または、CONFIG.SYS自体を削除します。AUTOEXEC.BATで、これらの文をコメント化します(コマンドをコメント化するには、コマンドラインの先頭に「REM」とスペースを入力します)。
サーバにメモリマネージャがある場合、NetWareは、メモリをNetWare自体で登録するのではなく、そのメモリマネージャを使って、使用可能メモリを判断します。メモリマネージャによっては、64MBを超えるメモリを認識できません。DOSデバイスドライバは、NetWareのメモリプールからメモリを取り込みます。
サーバを起動するためにWindows 95を使用していないことを確認します。Windows 95では、メモリマネージャが自動的にロードされます。
サーバBIOSが最新であることを確認します。
古いBIOSを使用している場合は、メモリの量が間違って報告されている可能性があります。新しいバージョンが取得可能な場合は、BIOSを更新します。
Reserved Buffers Below 16 MB SETパラメータ(Memoryカテゴリ)の設定が、300以上になっていることを確認します。
特に、必要なメモリが16MB未満のCD-ROMまたはテープデバイスを使用している場合、古いドライバでは、値を300以上に設定してください。
メモリが自動的に登録されていることを確認します。
メモリを手動で登録すると、メモリのフラグメンテーションが発生する場合があります。古いシステムボードによっては、メモリを手動で登録する必要がある場合がありますが、NetWareでメモリが自動的に登録されるように、新しいシステムボードにアップグレードすることをお勧めします。
メモリを手動で登録した場合は、サーバを再起動して、メモリを解放します。メモリを手動で登録し直さないでください。必要に応じて、システムボードをアップグレードします。
メモリエラーが、従来のボリュームのマウント中に発生するかどうかを検証します。
発生する場合は、サーバでメモリが不足している可能性があります。
メモリを一時的に解放するには、「サーバメモリを一時的に解放する」を参照してください。問題を解決するには、RAMを追加します。
(NetWare Remote ManagerまたはMONITORで)最長未使用時間(LRU)のピーク時間帯の平均値が、15分より長いことを確認します。
長くない場合は、サーバでメモリが不足している可能性があります。
メモリを一時的に解放するには、「サーバメモリを一時的に解放する」を参照してください。[LRU Sitting Time]を使ってメモリの調整を行うには、『Server Memory Administration Guide』の「Tuning File Cache」を参照してください。問題を解決するには、RAMを追加します。
メモリリークが発生していないかどうか確認します。
ネットワークトラフィックが増加しておらず、サーバに新しいアプリケーションがインストールされていないにも関わらず、[LRU Sitting Time]および[Long Term Cache Hits]の値が、徐々に減少していますか。
減少している場合は、サーバでメモリリークが発生している可能性があります。「メモリリークに関する問題を解決する」を参照してください。
それでも問題が発生する場合は、「トラブルシューティングの使用」のトラブルシューティング手順を実行し、Novell Knowledgebaseで検索して、Novellサポートプロバイダに連絡してください。
ロックされているデバイスに関するエラーを解決するには、次の手順を1つ以上実行します。
これらすべての手順を実行しても問題を解決できない場合は、Novellサポートプロバイダまたはドライブの製造元に連絡してください。
イベント制御ブロック割り当てに関するシステムメッセージは、最初にサーバを起動したとき、または、サーバが稼動中になってから一定時間経過後に、表示されることがあります。
これらのメッセージは、サーバが、十分なパケット受信バッファを取得できなかったことを示しています。通常、これらのバッファは、ECB(イベント制御ブロック)と呼ばれます。ECBの不足は、致命的な問題ではありません。しかし、LANまたはサーバに関する問題があることを示している場合があります。
ピーク時に高い負荷が発生する状態が繰り返される環境で、サーバが数日間稼動中である場合は、設定されているECBの最大数を超えたことによって、ECBに関するシステムメッセージが表示されることがあります。
このような状況が発生する原因が、メモリ需要の定期的なピークである場合は、現在の最大ECB割り当て数は変更せず、メモリ需要のピーク時にメッセージが表示される状態を維持します。
それ以外の原因が考えられ、サーバメモリに対する負荷が非常に高く、ECB割り当てに関するエラーが頻繁に発生する場合は、最大ECB割り当て数を大きくします。STARTUP.NCFファイルで、次のSETコマンドを使用します。
SET MAXIMUM PACKET RECEIVE BUFFERS=number
ECBに割り当てられているメモリは、他の目的には使用できません。
STARTUP.NCFで次のコマンドを使用すると、サーバが使用できる最小バッファ数も設定できます。
SET MINIMUM PACKET RECEIVE BUFFERS=number
サーバコンソールコマンドに関する問題を診断するには、次の条件が該当するかどうかを確認します。
サーバコンソールコマンドに関する問題を解決するには、次の操作を実行します。
可能である場合は、サーバをシャットダウンします。シャットダウンできない場合は、すべてのユーザがログアウトしてから数分間待ち、サーバを再起動します。
最も一般的な競合は、ネットワークボードが割り込み4に設定されている場合に、プリンタが、同様に割り込み4を使用するサーバのシリアルポートに接続されているときに発生します。
CD-ROMからファイルをコピーするときにキーボードがロックされる問題を診断するには、次の条件が該当するかどうかを確認します。
使用しているCD-ROMデバイスと、ネットワークオペレーティングシステムのインストールファイルがコピーされたボリューム(通常は、SYS)が含まれているディスクサブシステムが、SCSIバスを共有していると、そのボリュームにドライバをロードしたり、ファイルをコピーしたりするときに、キーボードがロックされる場合があります。設定の競合の例を次に示します。
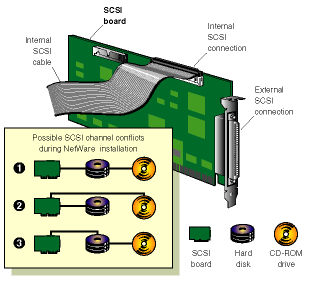
CD-ROMドライブをDOSデバイスとして設定するために使用したCD-ROMデバイスドライバを、CONFIG.SYSファイルから削除します。この操作によって、オペレーティングシステムCDをNetWareボリュームとしてマウントしたときに発生する可能性がある競合を防止できます。
このCDからファイルをコピーするときにキーボードがロックされる問題を解決するには、次の操作を実行します。
コンソールプロンプトが表示されるまで、<Alt>+<Esc>を繰り返し押します。
「DOWN」と入力します。
テキストエディタを使って、CONFIG.SYSファイルから、CD-ROMデバイスドライバを削除します。
更新したCONFIG.SYSファイルを保存します。
テキストエディタを使って、AUTOEXEC.BATファイルから、CD-ROMドライバへの参照をすべて削除します。
更新したAUTOEXEC.BATファイルを保存します。
<Ctrl>+<Alt>+<Del>を押して、サーバを再起動します。
(状況によって実行)サーバが、AUTOEXEC.BATファイルから自動的に起動しない場合は、SERVER.EXEファイルおよび他のブートファイルが保存されているサブディレクトリ(デフォルトでは、C:\NWSERVER)に移動し、DOSプロンプトで次のコマンドを入力します。
SERVER
(状況によって実行) ASPIデバイスドライバ(Adaptec*コントローラ用など)を使用している場合は、次のいずれかのコマンドを入力する必要があります。
AHAxxxx
xxxxには、Adaptecのボード番号を指定します。
または
ASPICD
または
CDNASPI
コンソールプロンプトで、「NWPA」と入力します。
(オプション)コンソールプロンプトで、「CD DEVICE LIST」と入力します。
ネットワーク上のすべてのデバイスに関連する番号のリストが表示されます。ボリューム番号を判別します。
コンソールプロンプトで、次のコマンドを入力します。
CD9660.NSS
CD MOUNT volume_name|number
コンソールプロンプトで、「NWCONFIG」と入力します。
|